Sizing connection pool
Intro
프로젝트를 할 때 Connection Pool Size는 당시 보던 책에 있는 Size를 따라서 설정했었습니다. 생각만큼 크지 않아도 된다는 헤드라인만 보고 예제에 나온 값 5를 그대로 사용했었는데, 뒤늦게 이에대한 의문이 생겨 Size를 어떻게 결정해야 할지 찾아보았습니다.
1
2
3
4
5
6
7
8
9
10
spring:
application:
name: limvik
datasource:
username: ${DATABASE_USERNAME}
password: ${DATABASE_PASSWORD}
url: ${DATABASE_URL}
hikari:
connection-timeout: 2000
maximum-pool-size: 5
Connection Pool 살펴보기
간단하게 Connection Pool이 무엇인지 살펴보겠습니다.
MySQL Connector/J 예제 살펴보기
먼저 예제를 통해 Connection을 살펴보겠습니다.
Java를 배우신 분이라면, 데이터베이스를 사용하기 위해 JDBC Driver를 불러오고 connection 을 만들어 SQL을 실행하는 것을 한 번쯤 해보셨을 겁니다.
아래는 MySQL 공식 문서(링크)에 있는 예제인데, 기본서에서 보던 코드와는 살짝 다르기는 하지만 간단한 리마인드니 그대로 살펴보겠습니다.
먼저 Driver를 불러오는 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
// Notice, do not import com.mysql.cj.jdbc.*
// or you will have problems!
public class LoadDriver {
public static void main(String[] args) {
try {
// The newInstance() call is a work around for some
// broken Java implementations
Class.forName("com.mysql.cj.jdbc.Driver").newInstance();
} catch (Exception ex) {
// handle the error
}
}
}
그리고 connection을 얻어오는 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
Connection conn = null;
...
try {
conn =
DriverManager.getConnection("jdbc:mysql://localhost/test?" +
"user=minty&password=greatsqldb");
// Do something with the Connection
...
} catch (SQLException ex) {
// handle any errors
System.out.println("SQLException: " + ex.getMessage());
System.out.println("SQLState: " + ex.getSQLState());
System.out.println("VendorError: " + ex.getErrorCode());
}
다음으로 문서에 있는 예제는 아니지만, connection을 통해 sql을 실행하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
public List<Deck> getDecksByUserId(User user, String ancestry) {
List<Deck> decks = new ArrayList<>();
String sql = "SELECT * FROM Decks WHERE user_id = ? AND ancestry LIKE ?";
try (PreparedStatement statement = conn.prepareStatement(sql)) {
statement.setInt(1, user.getId());
statement.setString(2, ancestry);
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
decks.add(new Deck(resultSet.getInt("id"),
resultSet.getInt("user_id"),
resultSet.getString("name"),
resultSet.getString("ancestry")));
}
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
return decks;
}
conn.prepareStatement(sql)과 같이 connection이 사용되고 있는 것을 볼 수 있습니다.
Connection 을 유지시키는 이유
이러한 Connection 은 URL(jdbc:mysql://localhost/test?user=minty&password=greatsqldb)만 봐도 TCP/IP 연결, 사용자 인증 등 뭔가 해야할 일이 많아보입니다.
모든 SQL 마다 연결하고 종료하기를 반복한다면, 불필요하게 자원을 낭비하게 됩니다. 자원을 낭비하므로 자연스럽게 응답 속도도 느려집니다. 그래서 불필요한 자원의 낭비를 막기 위해 Connection을 SQL 수행이 끝나고도 재활용할 수 있게 close하지 않고 그대로 유지시킵니다.
앞에서 Connection을 close 하지 않는다고 했는데, close 하지 않으면 한 가지 문제가 있습니다. Connection이 모두 사용 중일 때마다 계속해서 Connection을 새로 생성해서 늘어난다면, 모든 자원이 소진돼서 Crash가 발생할 수도 있습니다.
여러 사람이 사용한다면 1개의 Connection으로는 부족하고, 그렇다고 무한정 Connection을 늘리면 Crash가 발생할 수 있습니다. 그래서 Connection 갯수를 제한하고, Connection 상태 관리가 필요합니다.
Connection Pool
Connection Pool은 이름에서 쉽게 유추할 수 있듯, 여러 Connection을 관리하는 Pool 입니다.
아래 그림은 PostgreSQL 이기는 하지만, 제일 마음에 들어서 가져와봤습니다. 하나의 Client가 여러 Connection을 가질 수도 있는데, Client 당 Connection 표시는 잘못 이해할 가능성이 있는 것 같아 가장 마음에 들었습니다.
요청 시에 Connection Pool 에서 Connection을 얻어오고, 남아있는 Connection이 없다면 대기합니다. 그리고 획득한 Connection을 통해 Database와 통신합니다.
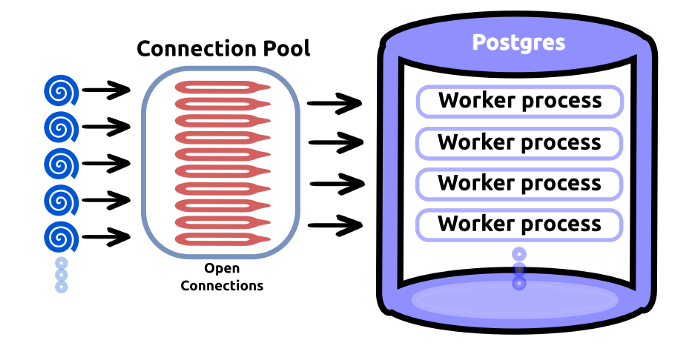
출처: Why do we need a Database Connection Pool?
Connection 이 많을수록 좋지 않을까?
Connection이 가득 차있으면, 대기 시간이 늘어나니까 자원이 허락하는 한도 내에서는 Connection Pool에 Connection이 많으면 많을수록 좋지 않을까 하는 생각이 듭니다.
그런데 데이터베이스 서버에서 Connection 하나 당 Thread 하나를 차지하고 있다는 것을 생각해보면, 꼭 그렇지는 않습니다.
Multithreading을 생각해보면, Multithread는 CPU가 놀지 못하게 만듭니다. 하나의 Core에서 실행 중인 Process의 여러 Thread 중 Disk I/O나 Network I/O와 같이 CPU 외부 요인으로 인해 시간이 오래 걸리는 작업을 하는 Thread가 있다면 I/O 작업 시 Block되어 응답을 기다리고, 다른 작업을 수행해야 하는 Thread가 Context Switching 되어 작업을 수행합니다.
그런데 CPU-intensive한 작업을 수행해야 하는 Thread가 늘어난다면, 서로 경합을 해야하고, Context Switching이 자주 발생해서 불필요한 자원 소모가 발생하게 됩니다.
이처럼 Thread가 많다고 무조건 성능이 좋아지지 않는 것 처럼, Connection이 많다고 성능이 좋아지지는 않습니다.
CPU-intensive한 작업만 한다면, Core 당 1개의 Thread가 있을 때 가장 최적의 성능이 나오게 됩니다.
몇 개의 Connection이 적당할까?
그래서 Connection Pool 에 Connection이 몇 개가 있어야 하는건지 의문이 생깁니다.
MySQL 문서 살펴보기
MySQL 공식 문서(링크)에 크기를 결정하는 것에 대한 조언이 있습니다.
Each connection to MySQL has overhead (memory, CPU, context switches, and so forth) on both the client and server side. … The optimal size for the connection pool depends on anticipated load and average database transaction time. … To correctly size a connection pool for your application, create load test scripts with tools such as Apache JMeter or The Grinder, and load test your application.
An easy way to determine a starting point is to configure your connection pool’s maximum number of connections to be unbounded, run a load test, and measure the largest amount of concurrently used connections. You can then work backward from there to determine what values of minimum and maximum pooled connections give the best performance for your particular application.
눈에 띄는 문장들을 가져와서 정리해보면, MySQL에 대한 각각의 Connection은 Client와 Server 측 모두에 Overhead가 발생합니다. 그래서 Application 마다 Connection Pool Size는 달라질 수 있으니까 부하 테스트(Load Test)를 통해서 동시에 사용되는 가장 큰 Connection 수를 찾고, Connection 수를 줄여가면서 최적의 Connection Pool Size를 찾으라고 합니다.
음… 납득이 되긴 하는데, 다른 자료를 찾아보니 시작점으로 사용할만한 공식이 있습니다. 최대값부터 시작하는 것 보다는 효율적으로 보입니다.
Connection Pool Size 공식
HikariCP Wiki에 Connection Pool Size와 관련된 글(링크)을 보면, 여러 내용과 함께 PostgreSQL에서 제공한 공식이 있습니다.
connections = ((core_count * 2) + effective_spindle_count)
core count에 HT(HyperThreading)의 Thread 수는 포함하면 안된다고 합니다. 저는 AMD라… PASS!
effective spindle count 는 HDD의 갯수를 의미합니다. SSD 에서도 잘 적용되는지는 아직 분석된게 없다고 합니다.
본인 컴퓨터의 Core 수를 잘 모르신다면 CPU-Z를 통해 쉽게 확인하실 수 있습니다. 혹은 CPU 모델명 확인하시고 검색하면 됩니다. 윈도우의 경우 윈도우 키 + Pause Break 를 눌러 시스템 정보에서 CPU 모델을 확인할 수 있습니다.
PostgreSQL 공식 문서(링크)를 보면 유지보수 및 모니터링 등을 위한 몇 개의 Connection 여유분을 더 추가해두라는 조언도 있습니다.
저의 오래된 컴퓨터는 Core 가 6개 입니다.
AMD Ryzen 5 3600X 6-Core Processor
따라서 2의 승수로 맞춰 16(=6 * 2 + 4)을 시작지점으로 해서 부하 테스트를 해봐야겠습니다.
부하 테스트
테스트 환경
제 로컬 환경에서 Connection Pool Size에 따른 경향성을 살펴보겠습니다. 하나의 Machine에서 Application Server와 Database Server가 같이 실행되고, 테스트 도구와 온갖 프로그램들이 많이 실행되고 있으므로 운영 환경과는 많이 달라서 경향성을 살펴보는 정도로 만족해야 하겠습니다.
대략적인 컴퓨터 사양은 아래와 같습니다.
- CPU: AMD Ryzen 5 3600X 6-Core Processor 4.10 GHz
- RAM: 16.0 GB
- SSD: 512 GB
- OS: Windows 11 Pro 22H2
- DB: MySQL 8.0.35
그리고 Spring Initializr 로 간단한 테스트용 Project를 만듭니다.
- Spring Boot 3.2.0
- Spring Web
- Tomcat 10.1.16
- MySQL Driver
- MySQL Connector/j 8.1.0
- Spring Data JDBC
- HikariCP 5.0.1
Properties 설정
Tomcat 설정은 기본값을 사용하여 thread pool은 기본값인 max 200과 min-spare 10을 그대로 사용합니다.
HikariCP 설정에서 Connection Pool Size를 앞서 정한 시작지점인 16으로 설정합니다.
1
2
3
4
5
6
7
8
9
spring:
application:
name: loadtest
datasource:
username: ${DATABASE_USERNAME}
password: ${DATABASE_PASSWORD}
url: ${DATABASE_URL}
hikari:
maximum-pool-size: 16
최소값인 minimumIdle은 기본값이 maximum-pool-size 입니다.
자세한 설정은 HikariCP GitHub(링크)에서 확인하실 수 있습니다.
Create Table
간단한 테이블을 만들고, 데이터를 하나 넣어줍니다.
1
2
3
4
5
6
7
8
9
CREATE TABLE `test`.`test` (
`id` INT NOT NULL AUTO_INCREMENT,
`testcol` VARCHAR(45) NULL,
PRIMARY KEY (`id`))
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8mb4
COLLATE = utf8mb4_0900_ai_ci;
INSERT INTO test(testcol) VALUES ('테스트');
Controller
test 테이블에서 데이터를 불러오는 Controller를 추가합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@RestController
public class TestController {
private final JdbcTemplate jdbcTemplate;
public TestController(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@GetMapping("/test")
public List<Map<String, Object>> test() {
String sql = "SELECT * FROM test";
return jdbcTemplate.queryForList(sql);
}
}
JMeter 설정
테스트 도구는 MySQL 문서에 언급된 JMeter를 사용합니다. 제대로 사용해본적이 없어서 자료(링크)를 참고해서 설정합니다.
먼저 Thread Group 의 설정은 아래와 같습니다.
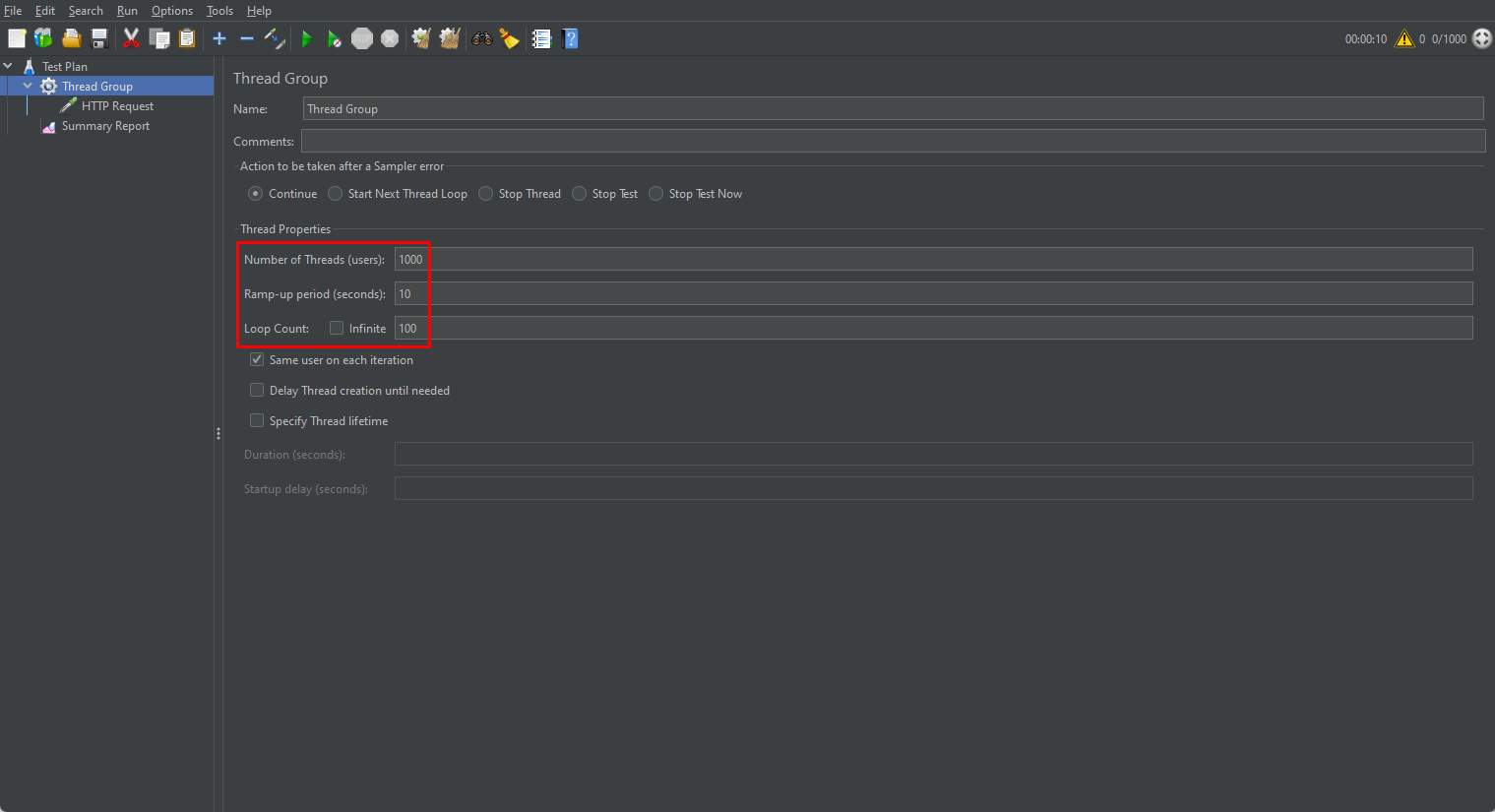
예상되는 부하를 잘 견디는지 보는게 아닌 Connection Pool Size 에 따라서 처리량 변화를 보기 위한 설정입니다.
- 가상의 User인
Number of Threads를 1000으로 설정 Ramp-up period는 10초로 설정하여, 10/1000 = 0.01초 마다 새로운 User가 요청을 보냅니다.Loop Count는 100으로 설정하여 0.01초 동안 하나의 User가 100개의 요청을 보냅니다.
DoS(Denial of Service) 공격 같은 느낌이 납니다.
HTTP Request 설정은 localhost/test 로 요청보내는 설정이라 굳이 화면을 추가하지는 않겠습니다.
Connection Pool Size 16 테스트 결과
throughput이 9938.4/sec 로 Error 없이 잘 처리합니다.

Connection Pool Size 10 테스트 결과
Connection Pool Size를 설정하지 않는 경우 기본값이 10 이어서, 10으로도 테스트를 수행합니다.
결과는 throughput이 9947.3/sec로 오차범위겠지만, 적은 Connection으로도 거의 동일한 결과가 나온다는 것을 볼 수 있습니다.

Connection Pool Size 5 테스트 결과
아무 생각 없이 예제를 따라서 설정했던 5로 테스트한 결과 9751.3/sec 으로 throughput이 감소한게 보입니다. 몇 번을 다시 해봐도 10으로 설정한 만큼은 안나옵니다.

Connection Pool Size 200 테스트 결과
재미삼아 Tomcat Thread 와 같은 Size로 설정하면 어떻게 되는지 테스트해보니, 6147.4/sec로 급격하게 저하되는 것을 볼 수 있습니다.

기타 테스트 결과
Core 수의 정확히 2배인 12, 16의 2배인 32 도 테스트를 해봤는데, 큰 차이가 없습니다.
Connection Pool Size 12 테스트 결과

Connection Pool Size 32 테스트 결과

Outro
테스트가 부실하기는 하지만, 테스트 결과 Connection Pool Size가 클 필요가 없다는 것은 확실하게 볼 수 있었습니다.
테스트 결과를 보면, 아무래도 자원의 여유가 있는 상황이라 Connection 몇 개 차이로 큰 영향이 없는 것으로 보입니다.
돈을 아껴야 하는 실제 운영 Server 에서는 실 운영 데이터를 바탕으로 최적의 Connection을 세세하게 조정해가면서 테스트 해보는게 좋겠습니다.
참고로, 아래 참고자료 중 HikariCP wiki - About Pool Sizing 에서 제일 마지막 즈음 Deadlock을 예방하기 위한 최소 Pool Size를 언급하는데… 다음 기회에 다뤄보도록 하겠습니다.