테이블 설계 회고
Intro
수강 중 팀 프로젝트를 하면서 어쩌다보니 테이블 설계할 때 항상 메인이 되었습니다. 순서대로 모두 훑어보는 것도 괜찮을 것 같아서 글을 적어봅니다.
첫 테이블 설계
첫 테이블 설계는 팀 프로젝트는 아니었고, Java를 배우고서 혼자서 플래시카드를 주제로 프로젝트 하면서 만들었습니다.
ERD
데이터베이스는 SQLite3를 사용하였습니다.
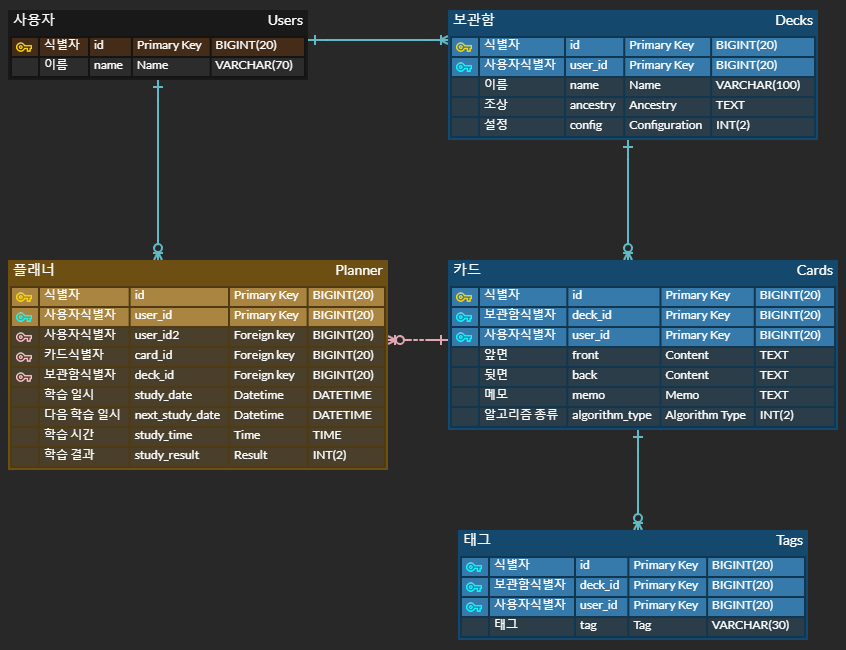
지금 보니 헛웃음이 나는데, 나름 성장했다는 증거겠죠…?
첫 번째 문제, 기본 키(Primary Key)와 외래 키(Foreign Key)로 동시에 사용되는 경우 중복 표시
플래너(Planner) 테이블에서는 사용자 식별자를 기본 키로 해두면 외래 키의 역할도 한다는 것을 놓칠까봐 겁나서 두 개 모두 표시(user_id, user_id2) 했습니다.
두 번째 문제, 잘못된 관계에 따른 잘못된 키 설정
ERD를 살펴보면 대부분의 관계를 식별 관계로 설정하여 기본 키가 복합 키로 설정됐는데, 이전에 작성한 글을 살펴보니 별 생각없이 관계를 설정했는지 왜 그렇게 했는지에 대해서 작성을 안해놨습니다. 쓸데 없는 글만 잔뜩…
여튼 어렴풋이 기억나는 이유는 부모 테이블이 사라졌을 때, 자식 테이블이 사라져야 한다면 식별 관계가 되어야 한다고 잘못 생각했게 기억납니다. 이는 참조무결성과 관련된 문제인데, 엄한데서 이를 나타내려고 한 것 같습니다.
잘못한 것 중에 하나인 Planner를 단수로 나타낸 것을 보면, 아무래도 사용자가 1개의 Planner만 갖는다는 것을 나타내려다가 이렇게 해놓은 것 같은데 이럴때 식별관계로, user_id만 기본키로 사용하면 되겠습니다.
부가적인 이유로 각 테이블의 기본키로 사용되는 id 컬럼은 단순히 데이터베이스의 인덱싱 성능을 위해 임의로 만들어 놓은 키 이므로, 해당 테이블의 특성을 나타낼 수 없다고 생각했던 것 같습니다. 그러니 기본키를 불필요하게 복합키로 만들어도 잘못됐다고 생각하지 못한 것으로 보입니다.
그런데 요즘은 분산 데이터베이스를 사용하는 경우 정수로 된 키는 충돌이 날 수 있어 UUID를 사용한다는 썰을 어렴풋이 들었는데 인덱싱 성능은 외려 떨어질테니, 단순히 데이터베이스 인덱싱을 위한 키라고 생각한 것은 잘못된 것임을 알 수 있습니다.
지금의 지식으로 볼 때 id 와 같은 키는 대리 키(Surrogate Key)라 불리며, 개념적으로 봐도 누군가를 대리한다는 것은 대리의 대상이 되는 키와 동등하게 취급해야 한다는 것입니다. 따라서 id 컬럼만으로 식별할 수 없을 때 새로운 기본 키를 추가하여 복합 키를 만들었어야 했습니다.
간단하게 GPT에게 대리키의 목적에 대해서 물어봤는데, 참고해볼만 한 것 같습니다.
Surrogate Key의 목적에 대한 GPT의 답변
서로게이트 키(surrogate key)는 데이터베이스에서 주로 사용되는 인공적으로 생성된 고유한 식별자입니다. 이러한 서로게이트 키를 사용하는 주요 목적은 다음과 같습니다:
고유성 보장: 서로게이트 키는 주로 자동 증가(auto-increment)나 다른 자동 생성 메커니즘을 통해 생성되기 때문에, 테이블의 모든 행에 대해 고유한 값을 갖습니다.
비즈니스 로직과 분리: 서로게이트 키는 비즈니스 로직과 무관하게 생성되므로, 비즈니스 요구사항의 변경에 영향을 받지 않습니다.
효율적인 색인: 고유하고 연속적인 숫자로 구성된 서로게이트 키는 인덱싱 및 검색에서 좋은 성능을 보입니다.
데이터 정합성 유지: 자연 키(natural key)가 변동될 가능성이 있을 때, 이러한 변동으로 인한 외래 키(foreign key)의 수정 및 관련된 다른 문제를 피하고자 서로게이트 키를 사용합니다.
데이터 통합 및 마이그레이션 용이: 여러 시스템이나 데이터베이스에서 데이터를 통합하거나 마이그레이션 할 때, 각 시스템이나 데이터베이스에서 사용되는 자연 키가 충돌할 수 있습니다. 이러한 문제를 피하기 위해 서로게이트 키를 사용하면 고유한 식별자를 통해 데이터의 통합이나 마이그레이션을 더욱 간편하게 할 수 있습니다.
구조적 유연성: 특히 복합 키(composite key)를 사용해야 할 경우에 데이터 구조 변경에 따른 복잡성을 줄이기 위해 서로게이트 키를 사용할 수 있습니다.
그러나 서로게이트 키가 갖는 이점들에도 불구하고, 데이터 모델링 시에는 해당 도메인과 요구 사항을 충분히 고려하여 서로게이트 키 사용 여부를 결정해야 합니다.
마무리
앞서 중간에 언급했던, 사용자 당 1개의 Planner를 갖는다고 테이블명을 단수로 작성했던 문제가 있기는 하지만 당연히 복수로 변경하면 되기에 크게 다룰 내용은 아닌 것 같습니다.
MySQL 생각하면서 보관함의 제목을 왜 VARCHAR(100)으로 했지? 하고 생각했는데, SQLite3 를 사용해서 영문자나 한글이나 동일하게 길이로 판단합니다.
두 번째 테이블 설계
두 번째는 드디어 팀 프로젝트의 시작.
개발 관련 온라인 스터디그룹을 주제로 게시판을 만드는 프로젝트였습니다.
ERD
이 팀 프로젝트부터 MySQL만 사용하기 시작합니다.
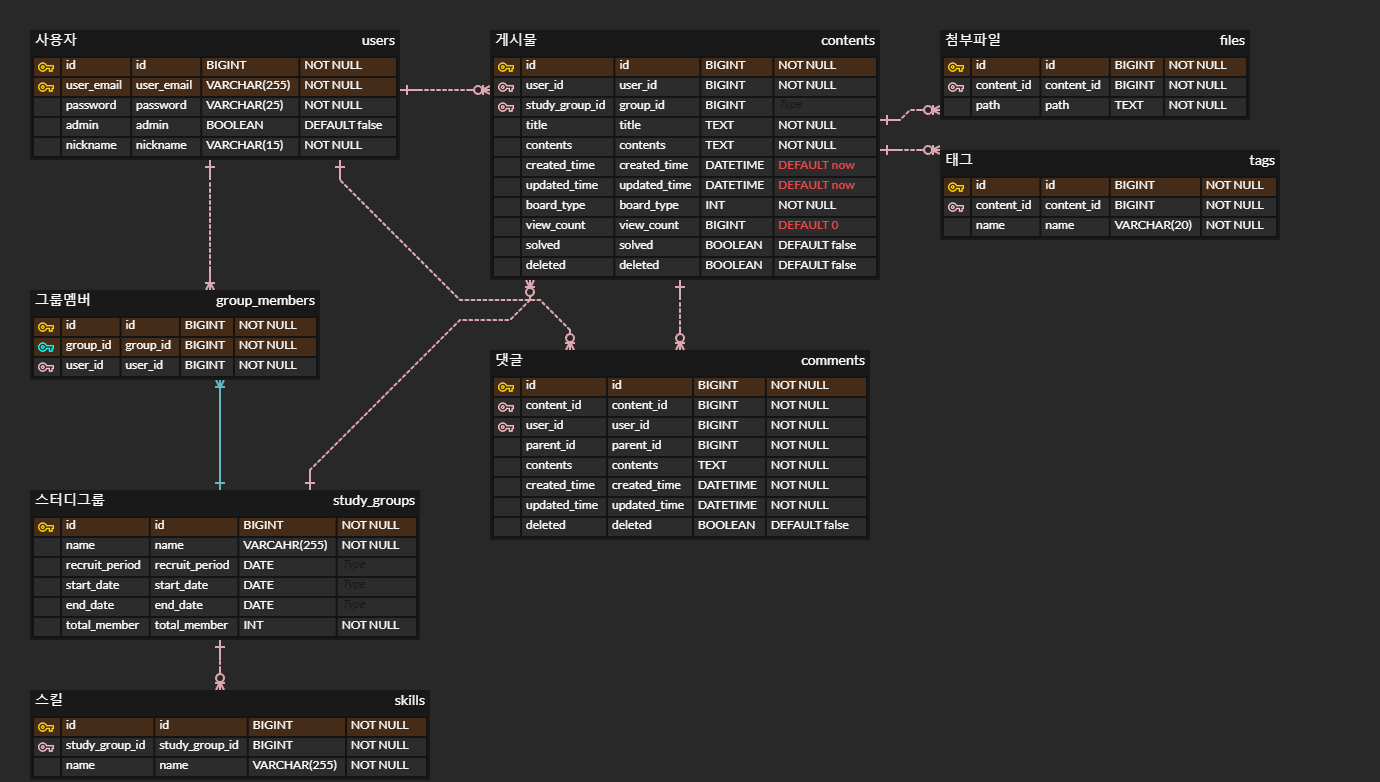
프로젝트 기간이 짧아 급하게 1시간 좀 넘게 투자해서 급하게 완료했는데, 요구사항도 오락가락 하는 판에 시간도 부족해서 쉽지 않았습니다. 정신이 없었는지 두 칸을 모두 동일하게 컬럼명으로 적었네요.
첫 번째 문제, 불필요한 복합키 설정과 이상한 관계
사용자(users) 테이블의 기본키를 복합키로 설정한 것을 보니, 여전히 대리 키(Surrogate Key)에 대한 인식이 변하지 않았음을 볼 수 있습니다.
그래도 다른 테이블에는 비식별관계를 설정해서 쓸데 없이 복합키를 만들지 않은 것을 보면, 뭔가 이상함을 감지하기는 했던 것 같습니다.
그런데 이상함을 감지하고 한 행동이 좀 이상합니다. 댓글(comments) 테이블에 사용자 테이블과 관계를 설정했는데, user_email이 외래키가 아닙니다. 뭔가 이상함을 느끼기는 했지만, 수정해보려다가 이상한 테이블이 돼버렸습니다. 애초에 복합키로 설정하지 말았어야 할 것을 설정하다 보니 이런 문제가 발생합니다.
두 번째 문제, 이상한(?) 다대다 관계 테이블
스터디그룹에 여러 사용자가 참여할 수 있고, 사용자가 여러 스터디그룹을 개설할 수도 있으니 다대다 관계가 됐습니다. 그래서 별도의 테이블(group_memebers)로 관계를 나타냈습니다.
이상한 점은 왜 대리 키를 만들었는지 모르겠습니다. user_id와 group_id로만 복합키로 해서 테이블을 만들었으면 됐을 텐데, 급하게 만들다보니 어렴풋이도 왜 그랬는지 안떠오릅니다.
그래도 이상했던 것을 알아차렸었는지, 최근에 했던 팀 프로젝트에서는 이렇게 하지는 않았습니다.
세 번째 문제, 잘못된 데이터 타입
잘못된 데이터 타입 중 한가지는 게시물의 내용에 TEXT 를 적용한 것입니다. 당시에 문자열을 위한 가장 큰 데이터 타입이 TEXT인걸로 잘못 알고있었습니다.
JPA를 처음 사용해보면서 @Column(columnDefinition = “TEXT”) 를 사용하기 싫어, 방법을 찾으면서 글(링크)을 썼는데, 이때 TEXT의 종류도 다양하다는 것을 처음 알아서 여러가지로 대혼란의 글이 됐습니다.
사실 게시판 생각하면 TEXT 정도로도 충분하기는 한데, 항상 예외라는게 존재하기도 하고, TEXT가 가장 큰 데이터 타입으로 착각하고 사용한 것이기 때문에 잘못된 데이터 타입을 설정한 것으로 분류했습니다.
다른 한 가지는 VARCHAR 데이터 타입의 길이를 한글 바이트 수를 고려하지 않고 설정한 것입니다. 되도록 정확한 길이를 지정하려고 했는데, 지금 생각해보니 한글, 영문 상관없이 그냥 정말 길이를 지정하였습니다. 나머지는 시간 내에 판단이 안서서 다른 사람들이 만든 테이블은 그냥 냅다 255 하길래 255로 지정했습니다. 왜 255인지에 대해서도 자료만 모아두고, 정리를 안해서 아직도 왜 255인지 모르긴 합니다. 자신있게 255로 쓰려면 이와 관련해서도 자료 모아둘겸 글로 써야겠습니다.
네 번째 문제, 비효율적인 스킬 테이블
스킬(skills) 테이블은 각 스터디그룹이 학습하려는 스킬을 저장하는 테이블입니다. 1대다 관계로 설정해서 각 스터디그룹이 학습하려는 스킬을 각자 마음대로 저장하도록 하였습니다.
지금 생각하기에는 개발에 사용되는 스킬이 한정적이므로 테이블 공간도 아끼고, 스킬별로 스터디그룹을 정렬 혹은 검색할 때 편하게 하려면 다대다 관계로 설정하는게 더 나았을 것 같습니다. 중구 난방으로 사용자마다 동일한 스킬을 다르게 입력하는 것 보다 더 깔끔할 것 같기도 합니다.
다섯 번째 문제, 마스터 테이블 없음
게시물(contents) 테이블의 board_type이 있는데, 이게 정확히 무엇인지 참조할 수 있는 마스터 테이블을 만들지 않았습니다. 그래서 개발 중에 어떤 게시판을 어떤 순서로 배치할지 팀원끼리 혼란이 있었던 기억이 납니다.
마무리
뭔가 잘못된 것이 더 있을 것 같기는 한데, 현재의 지식으로 보이는 것은 이정도입니다.
세 번째 테이블 설계
세 번째는 도대체가 뭘 만들자는 건지 이해가 안돼서 고통스러웠던 프로젝트였습니다.
주제는 지역기반 정보 공유 커뮤니티였습니다.
ERD
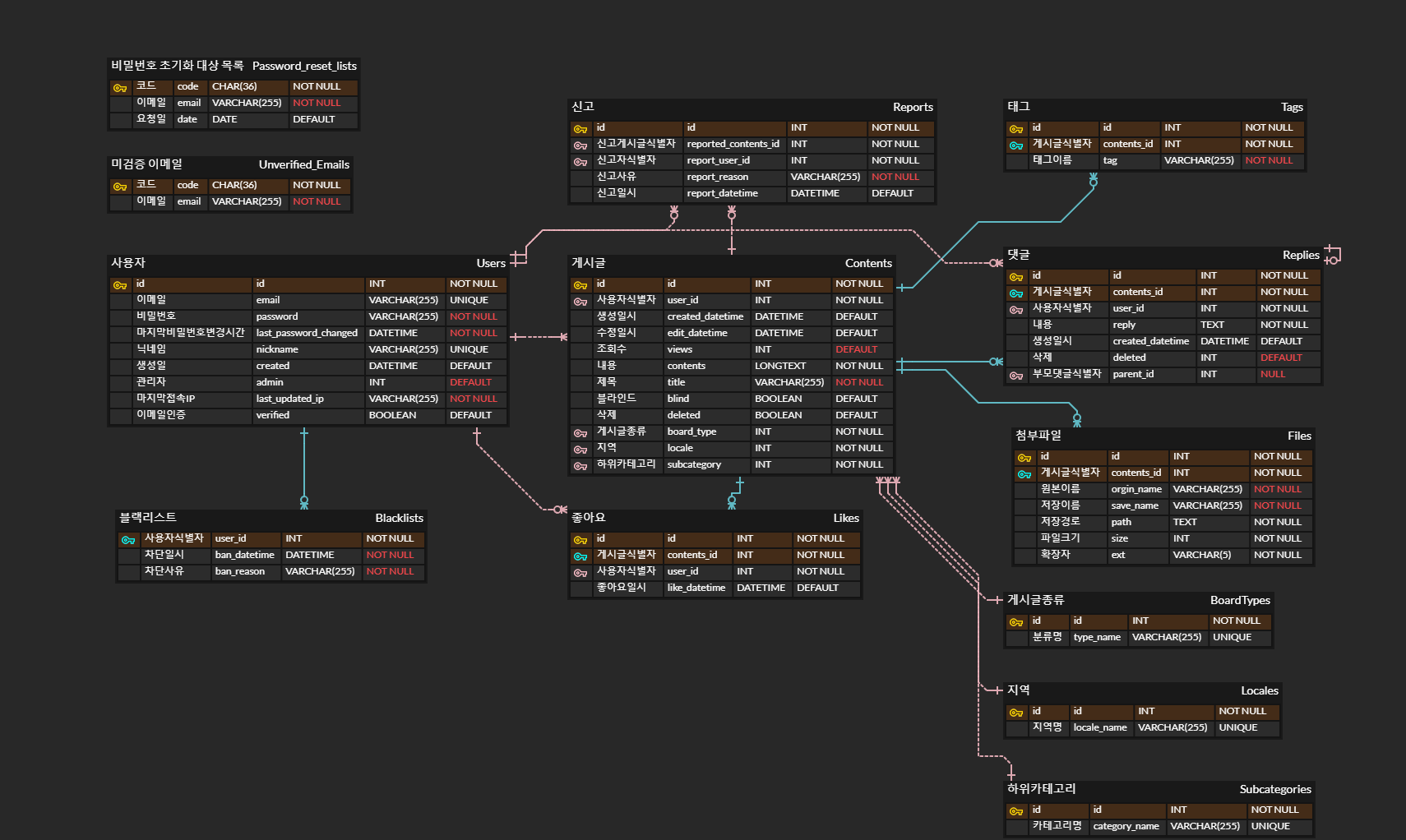
태그(Tags), 댓글(Replies), 첨부파일(Files), 좋아요(Likes) 테이블을 보면 여기서도 여전히 불필요하게 식별 관계로 설정하고 복합키가 된 것을 볼 수 있습니다. 앞에서도 다룬 문제니 따로 문제로 다루지는 않겠습니다.
2~3시간 정도 걸린 것 같은데, 테이블에서 사용할 용어들을 모두가 익숙할만한 단어로 정하는데 시간이 가장 많이 걸렸던 기억이 납니다.
그리고 더 긴 기간 수행할 프로젝트고 사람도 많으니, 더 잘할 수 있을거라는 착각에 빠져서 ERDCLOUD에 있는 다른 공개된 테이블도 참고해서 마지막 접속 IP 등등 넣을 생각을 못해봤던 컬럼들도 추가해봤습니다.
무지성 VARCHAR(255) 설정 등 기존의 잘못했던 것을 반복하고 있습니다. 가장 기억에 남는 새롭게 잘못한 것은 테이블 이름에 대문자를 사용했던 것이었습니다.
가장 큰 잘못. 테이블 이름에 대문자를 사용
테이블 이름에 대문자를 사용해도 사실 설계할 때는 문제가 없기는 한데, 배포하면서 문제가 생깁니다. 윈도우에서 작업하고, 리눅스에 배포하니 파일시스템이 달라서 윈도우는 대소문자를 신경쓰지 않고 동일한 파일로 취급하는 반면, 리눅스는 대소문자가 다르면 다른 파일이 됩니다.
관련해서 아예 따로 글로 정리(링크)하기도 해서, 자세한 내용이 궁금하신 분들은 링크를 참조하시면 됩니다.
설계 때 부터 그냥 소문자를 사용하는게 좋은 것 같습니다.
마무리
이 프로젝트 테이블 설계는 설계 자체의 어려움 보다는 이해되지 않는 기획과 협의해야 할 요구사항에 대해 개발자가 그런걸 뭐하러 하느냐는 상황 등 다른 외적인 어려움이 많았습니다.
그래서 그런가 전혀 발전한 모습을 볼 수 없는 테이블 설계였습니다.
네 번째 테이블 설계
드디어 마지막 테이블 설계입니다. 괜찮은 채용 공고를 팀원끼리 공유하고, 공유한 채용 공고는 회사에 대해 자세히 알아보기 전에 보고싶은 정보만 보고싶어서 만들었습니다.
ERD
이전 프로젝트에서 같이 했던 팀원들이라, 더욱 발전된 모습으로 프로젝트에 참여할 수 있을거라 기대하고 이전 프로젝트보다 기간은 짧지만 비슷한 수준의 크기로 설계했습니다.
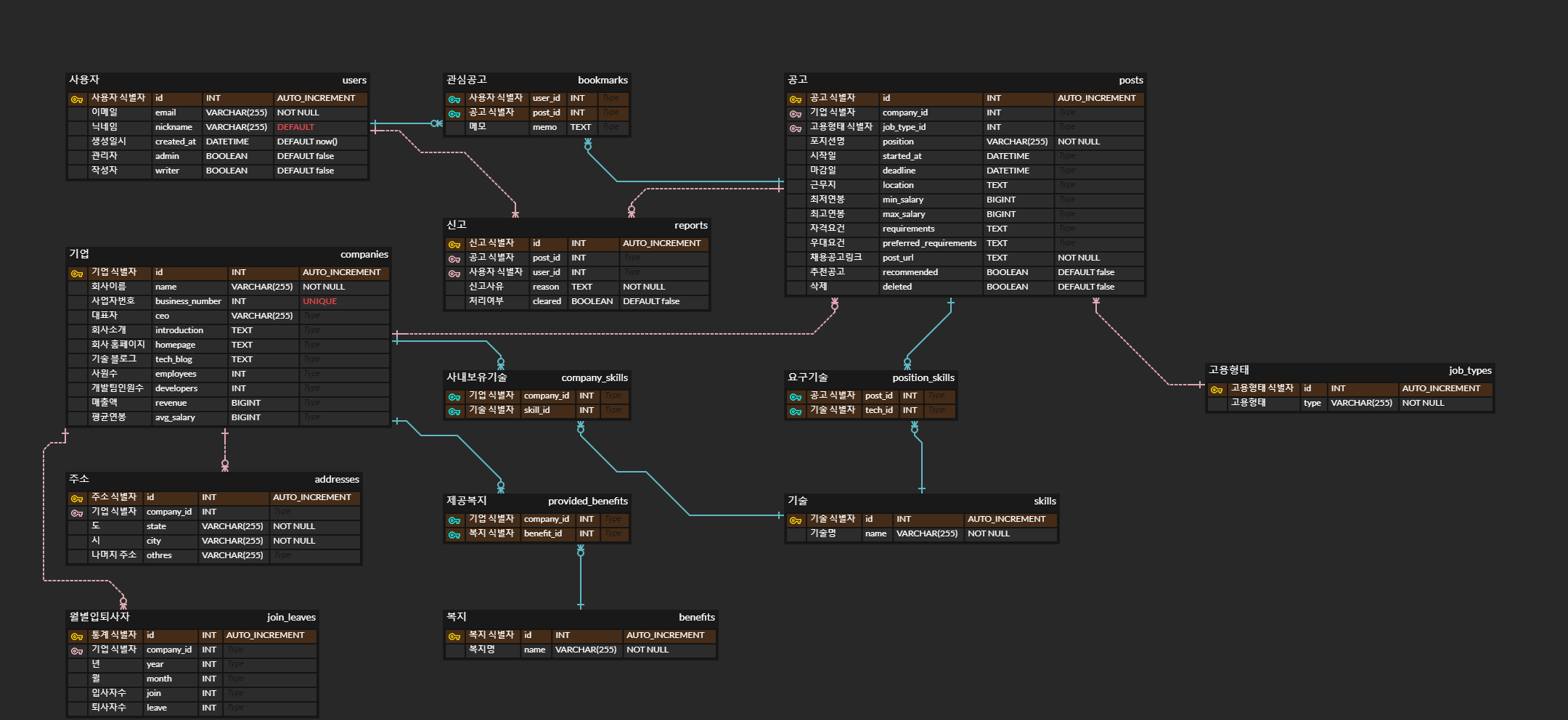
뭔가 할 말이 많지만, ERD와는 상관없는 내용은 개별 프로젝트를 회고하며 적어봐야겠습니다.
가장 큰 잘못. 감당할 수 없는 복잡함
다대다 관계에 있는 테이블을 Join 을 통해 가져오는 것을 처음해보니, 팀원들은 제가 만들때까지 반쯤 포기해버린 상황이 돼버렸습니다. MyBatis 용 ResultMap만 대략 50줄이라 쉽지 않기는 했습니다. 현실에서는 50줄은 별거 아닐 수도 있겠죠…?
설계 때 부터 View 를 고려해서 팀원들이 감당할 수 있는 수준으로 쿼리 작업을 할 수 있게 했으면 좋지 않았을까 하는 생각이 듭니다.
추가로 찾은 잘못. 역할 각각을 컬럼으로
도메인 설계에 대한 내용을 보다가, 사용자의 역할을 Roles 로 표현한 것을 보고 갑자기 잘못한게 떠올라서 내용을 추가합니다.
사용자(users) 테이블에서 관리자(admin)와 작성자(writer) 모두 역할로 묶을 수 있는데 개별적인 컬럼으로 만들어버렸습니다. 처음에 관리자 역할만 있다가, 먼 미래까지 생각했을 때 일반 사용자도 채용 공고를 공유할 권한을 주기 위해서 작성자(writer)라는 역할을 추가하면서 이렇게 됐던걸로 기억합니다.
이전부터 구체적인 역할을 컬럼으로 추가해왔었는데, 확장성을 생각하면 조금 더 추상화된 역할(Roles) 컬럼을 만드는게 더 맞는 것 같습니다.
마무리
이제 더 개선할 수 있는 지식을 어디서 제 수준에 맞게 얻을 수 있는지 몰라 길을 잃은 상태입니다. 그래서 뭔가 잘못한게 있는 느낌은 드는데, 뭘 잘못했고 어떻게 개선해야할지 너무 궁금합니다.
Outro
이전에 했던 ERD를 살펴보니, 최근까지도 잘못하고 있었다는게 보였습니다. 이제 지식이 짧아 더 개선해볼 방법을 찾기 위해서 책을 찾아봤고, 적합한 책을 찾았는데… 절판이네요.
중고책이라도 당연히 있을 줄 알았더니 엄청 안팔렸나 봅니다. 중고책도 안보입니다. 목차가 너무 딱 지금 고민들을 잘 나타내는데 아쉽습니다.
아래 시리즈도 눈에 띄기는 한데, 아직 이정도 수준까지는 부담되니… 일단 링크 저장용으로 추가합니다.
관계형 데이터 모델링 프리미엄 가이드
관계형 데이터 모델링 노트
김기창의 데이터 모델링 강의
그나마 지금이라도 개선해볼만한 것은 무지성으로 VARCHAR(255)를 설정했던 것이니 자료를 좀 찾아봐야겠습니다.