Multithreading 구현 모델과 Java
Intro
운영체제 기초 과목을 KMOOC에서 수강하면서 Multithreading 부분을 배우고 있습니다. 강의에서는 C언어를 예시로 사용하다보니 제가 주로 사용하는 언어인 Java에서는 어떻게 내용이 연결이 되는지 궁금해서 찾아본 내용을 공유합니다.
Multithreading
먼저 간단하게 Multithreading과 관련된 내용을 살펴보겠습니다.
Multithreading 등장 배경
병렬작업의 수요가 증가하던 1980년대에는 병렬화 할 수 있는 대상이 Process 밖에 없었습니다. 하지만 Process를 병렬화 하기 위해 Code / Data / Heap / Stack Segment에 있는 데이터를 전부 복사하여 여러 Process를 생성하는 것은 비용이 너무 많이 드는 작업이었기 때문에, 오버헤드가 너무 커서 병렬화 작업의 주 수요처였던 과학기술분야의 연산 작업에 사용하기에는 부적합했습니다.
그래서 엔지니어들은 새로운 하드웨어를 추가하기보다는 개념적으로 Process 내에서 하드웨어 자원과 작업을 수행하는 Thread를 분리하여 다중화 할 수 있게 하였습니다.
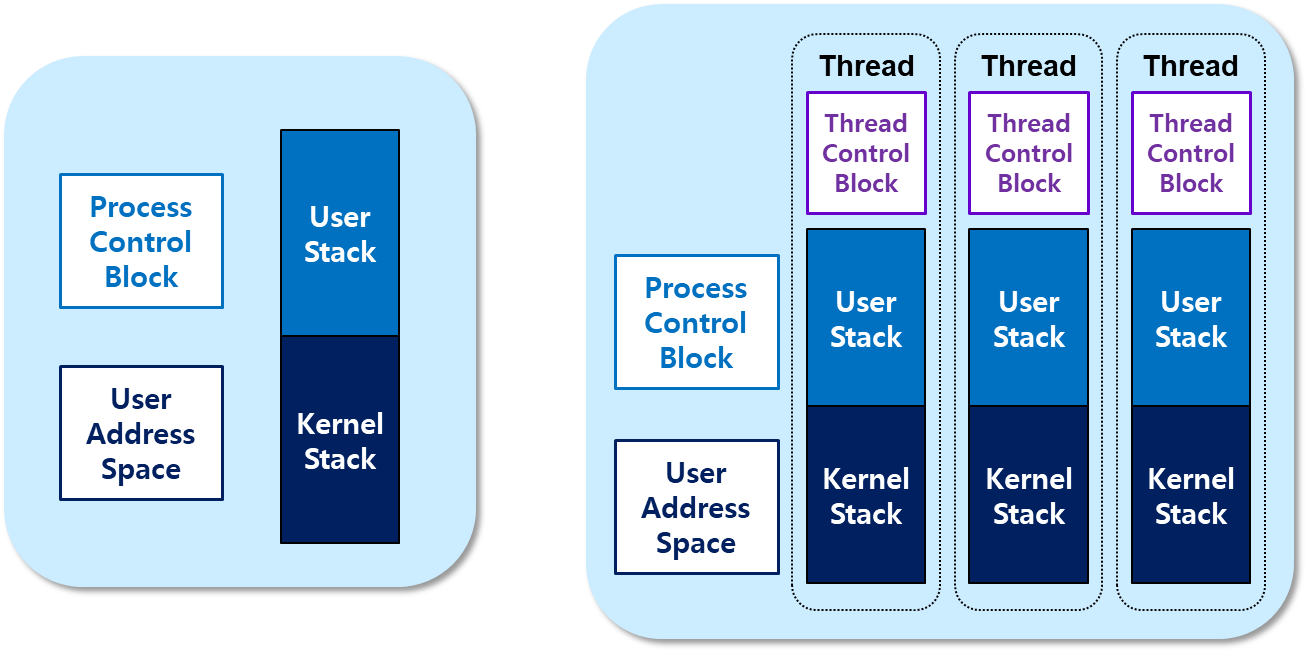
출처: KMOOC 운영체제의 기초 강의 4-5-1 Multithreading
개념적인 아이디어이기 때문에 다양한 구현 모델이 있습니다.
Multithreading 구현 모델
Multithreading의 구현 모델은 총 3가지가 있습니다. User-Level Threading, Kernel-Level Threading, Hybrid Threading 이 있습니다.
먼저 User-Level Threading 부터 살펴보겠습니다.
User-Level Threading
User-Level Threading은 이름 그대로, 사용자의 코드가 존재하는 User-Level에서 Multithreading을 구현한 모델입니다.
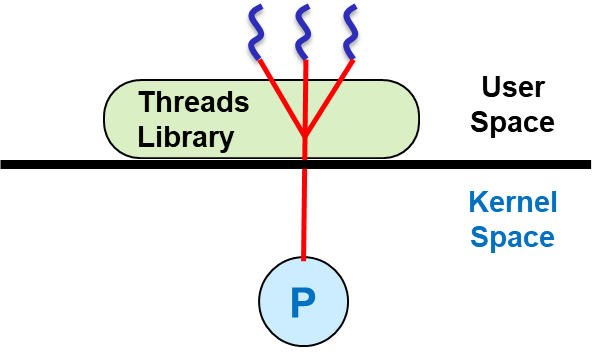
출처: KMOOC 운영체제의 기초 강의 4-5-3 Multithreading
그림과 같이 User-Level에서만 Multithreading을 구현하기 때문에, OS 입장에서는 Single Thread 모델과 동일합니다. 다수의 User-Level Thread가 하나의 Kernel-Level Thread에 대응되므로 M:1(Many to One) 모델이라 부르기도 합니다.
OS 입장에서는 Single Thread와 동일하고, OS에서 Thread 스케줄링을 수행하는 것이 아니어서 Interrupt를 발생 시켜 User Mode와 Kernel Mode를 오가는 등의 복잡한 절차를 거칠 필요가 없으므로 비용도 적게 들어갑니다. 그래서 Kernel-Level Thread 대비 자원을 적게 소모한다는 장점이 있습니다.
그런데 Blocking I/O 작업을 한다면, OS 입장에서는 당연히 관리하고 있는 Single Thread가 Blocking 되므로 User-Level Thread가 모두 Blocking 되어 버리는 문제가 있습니다.
이게 무슨 병렬 작업인가 싶지만, 듣고있는 강의의 교수님 말씀에 따르면 과학기술분야의 연산에서는 Synchronous 한 작업이 많아서 큰 문제가 아니었다고 합니다. 또 Kernel-Level Threading을 지원하려면 OS에서 지원을 해줘야하는데, OS를 뜯어고치는게 쉬운 일은 아니었을 것입니다. 그래서 Multithreading을 지원하지 않는 OS 가 많았던 시기에는 User-Level Threading을 지원하는게 이식성이 좋은 방식이라고 볼 수도 있겠습니다.
하지만 컴퓨터를 과학기술분야에서 연산하는데만 사용했던 것은 아니었기 때문에, 당연하게도 Kernel-Level Threading이 필요해 보입니다.
Kernel-Level Threading
Kernel-Level Threading은 OS에서 하나의 Process에 여러 Kernel Thread를 생성하고, User Thread에 1:1로 매핑 및 스케줄링을 수행합니다. Thread를 OS가 관리하는 것입니다. 그래서 1:1(One to One) 모델이라고도 합니다. 이전에 언급했듯 OS에서 지원해야 사용 가능하지만, 현대 OS는 당연하게도 모두 지원합니다.
User-Level Threading이 라이브러리를 통해 User-Level 에서 관리하는 Thread를 생성한다면, Kernel-Level Threading은 시스템 콜을 통해 Kernel-Level에서 직접 생성하고 관리하는 Thread가 생성됩니다.
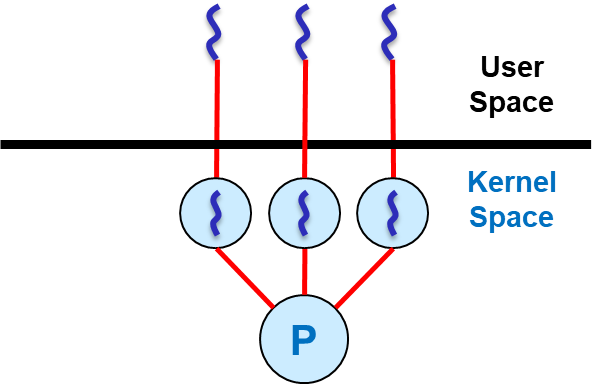
출처: KMOOC 운영체제의 기초 강의 4-5-3 Multithreading
그리고 Kernel-Level Threading은 User-Level Threading의 단점을 해결해서 장점이 되고, 또 반대로 User-Level Threading의 장점이 사라져 Kernel-Level Threading의 단점이 됩니다.
Kernel-Level Threading은 OS에서 Thread 스케줄을 관리하므로, Blocking I/O 작업을 수행해도 Process 전체가 중단되지 않습니다. 자세한 부분을 모르더라도 Multithreading 이라고하면 생각나는 방식입니다. 하지만 OS에서 관리하는 만큼 User Mode와 Kernel Mode를 오가면서 복잡한 절차를 거쳐야 하므로, Thread 생성 비용이 많이 발생합니다.
그래서 이 둘의 장점만을 취한 Multithreading 모델도 등장합니다.
Hybrid Threading
Hybrid Threading은 User-Level Threading과 Kernel-Level Threading의 장점만 모았습니다. 아래 그림과 같이 여러 개의 User-Level Thread가 여러 개의 Kernel-Level Thread에 매핑될 수 있어 M:N(Many to Many) 모델이라고 도합니다.
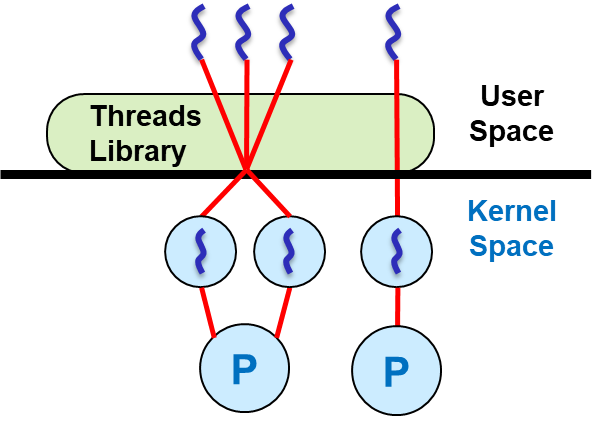
출처: KMOOC 운영체제의 기초 강의 4-5-3 Multithreading
User-Level에서는 물리적인 CPU보다 많은 가상의 CPU가 있는 것으로 볼 수 있습니다. Intel의 Hyper Threading과 비슷해 보이지만, Intel 은 하드웨어적으로 지원한다고 봐야겠죠.
여튼, 당연히 이 모델을 사용해야 할 것 같아 보이지만 Wikipedia에 나온 내용에 따르면 User-Level Threading의 스케줄링과 Kernel-Level Threading의 스케줄링에 대한 조정이 필요한데, 이에 대한 비용이 많이 들어가며, 복잡합니다. 자세한 내용은 자료 찾기도 쉽지않고, 지원 하던 OS도 중단하는 모델이라 이정도만 살펴보겠습니다.
그럼 Java에서는 세 가지 중에서 어떤 모델을 사용하고 있을지 한 번 살펴보겠습니다.
Multithreading Model in Java
Java에서 Thread 클래스를 다루어보셨던 분은 감이 오시겠지만, 당연하게도 Java에서는 Kernel-Level Threading을 구현하고 있습니다. 그리고 각 Thread는 ThreadLocal 클래스를 통해 격리된 저장공간을 사용할 수 있습니다.
재미있는 점은 Java 도 과거에 1.2 버전까지는 Green Thread라고 부르는 User-Level Threading만 지원했었습니다. 그리고 1.3 버전부터는 Green Thread를 버리고 Kernel-Level Threading을 도입하여 개발자가 코드에서 Thread를 생성하면, OS의 Kernel Thread와 1:1로 매핑합니다.
Write Once Run Everywhere 를 외치던 Java 였기 때문에 처음에는 User-Level Threading으로 구현하고, Multithreading은 개념적인 구현이기 때문에 OS 마다 지원하는 Multithreading 구현이 달라서 이에 대응하는 시간이 필요하지 않았을까? 하는 뇌피셜을 펼쳐봅니다.
그런데 Java에서 버려졌던 User-Level Threading 모델이 Virtual Threads 라는 이름으로 다시 등장합니다.
JEP 444: Virtual Threads
JDK 21 부터 지원하는 Virtual Threads의 JEP 문서를 살펴보면, Tomcat 과 같은 thread-per-request 모델 사용 시 Kernel-Level Threading 으로 인한 단점들을 지적합니다.
Unfortunately, the number of available threads is limited because the JDK implements threads as wrappers around operating system (OS) threads. OS threads are costly, so we cannot have too many of them, which makes the implementation ill-suited to the thread-per-request style. If each request consumes a thread, and thus an OS thread, for its duration, then the number of threads often becomes the limiting factor long before other resources, such as CPU or network connections, are exhausted. The JDK’s current implementation of threads caps the application’s throughput to a level well below what the hardware can support. This happens even when threads are pooled, since pooling helps avoid the high cost of starting a new thread but does not increase the total number of threads.
요약해보자면 Kernel Thread(=OS Thread)는 비용이 많이 들고, JDK는 사용할 수 있는 Thread 수에 제한을 두고있어, 하드웨어 자원에 여유가 있어도 자원을 제대로 활용하지 못하게 된다는 이야기 입니다.
이어진 내용으로는 thread-per-request 모델의 단점을 해소하기 위해 Netty와 같은 비동기 서버를 사용하는 경우, 너무 복잡해서 개발 비용이 많이들어가는 단점이 있다고 합니다. 그래서 아래와 같이 많은 수의 Virtual Thread를 더 적은 수의 Kernel Thread에 매핑하는 방식으로 구현다고 합니다. Hybrid Threading의 느낌도 납니다.
Just as operating systems give the illusion of plentiful memory by mapping a large virtual address space to a limited amount of physical RAM, a Java runtime can give the illusion of plentiful threads by mapping a large number of virtual threads to a small number of OS threads.
기존의 익숙한 thread-per-request 모델을 사용하면서 비동기 스타일과 동일한 효과를 낼 수 있는 것입니다. User-Level Threading 모델에서 하나의 Thread가 Blocking I/O 작업을 하면 모든 Thread가 멈춰버리는 단점을 아래와 같이 runtime 이 non-blocking OS 호출을 하고, Virtual Thread를 일시 중지(suspends)하는 방식으로 해결하였습니다.
When code running in a virtual thread calls a
blocking I/Ooperation in thejava.*API, the runtime performs anon-blocking OS calland automatically suspends the virtual thread until it can be resumed later.
그런데 사용하는 것이 쉽지만은 않습니다. Virtual Threads 에 적합한 구현이 필요합니다. User-Level Threading의 특성에 맞게 구현하는게 필요하겠죠. 특히나 Kernel-Level Threads 를 사용해오던 것 처럼 Pooling 해서 사용해서는 안된다고 강조합니다.
Virtual threads are cheap and plentiful, and thus
should never be pooled: A new virtual thread should be created for every application task. Most virtual threads will thus be short-lived and have shallow call stacks, performing as little as a single HTTP client call or a single JDBC query. Platform threads, by contrast, are heavyweight and expensive, and thus often must be pooled. They tend to be long-lived, have deep call stacks, and be shared among many tasks.
그래도 User-Level Threading과 Kernel-Level Threading 의 차이점을 이해하면 추후 Virtual Threads 를 더 원활하게 사용할 수 있지 않을까 기대하면서 마무리 하겠습니다.
참고자료
- KMOOC - 운영체제의 기초
- Wikipedia - Thread
- https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/4_Threads.html
- Wikipedia - Green Thread
- Project Loom
- JEP 444: Virtual Threads
- When Quarkus meets Virtual Threads
- Green Threads vs Non Green Threads
- Loom–Virtual-Threads-and-Structured-Concurrency-in-the-JDK-19.pdf
A thread is not cheap!
- Thread startup time: ~1ms
- Thread memory consumption: 2MB of stack
- Context switching: ~100ms (depends on the OS)
Having 1 million platform threads is not possible!
Outro
Virtual Threads는 궁금하지만 아직 깊게 다룰때가 아닌 것 같아, 몇 년 후에나 보게되지 않을까 생각했습니다. 그런데 Thread를 살펴보다보니 계속 튀어나와서 겸사 겸사 Virtual Thread가 무엇인지 간단하게 살펴볼 수 있는 좋은 시간이 됐습니다.