게시판 댓글, 디렉토리 같은 계층 구조는 관계형 데이터베이스에 어떻게 저장하나요?
Intro
이전에 데이터베이스 설계 연습을 하면서 작성한 글(링크)에서 개념 데이터 모델을 ERD로 그려봤습니다. 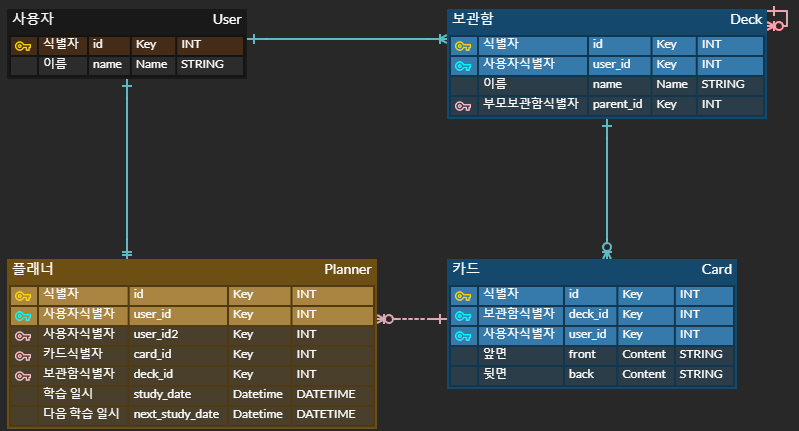
그리고 혼란스러운 것 중에 하나를 아래와 같이 적어놓았습니다.
보관함은 디렉토리 구조로 만들려고 계획하고 있습니다. 그런데 여러 계층을 갖게 될 때 상위의 모든 보관함과 하위의 모든 보관함이 다대다 관계를 갖는건지 아니면, 바로 위아래 계층만 고려해서 일대다 관계가 되는건지 고민이 됩니다.
고민을 하다보니 디렉토리의 용량을 구하기 위해서는 하위 디렉토리를 먼저 계산하기 위해 후위 순회(Postorder Traversal)를 해야 한다는 것과 트리(Tree) 구조에서 수행해야 한다는 것이 기억났습니다.
그래서 how to store tree structure in database 와 같은 키워드로 검색해보니 트리 구조 혹은 계층 구조를 데이터베이스에 담으려는 경우가 제품 카탈로그, 게시판 댓글 등 다양한 경우가 있다보니 패턴까지 존재했습니다.
각 패턴을 모두 상세히 다루지는 못하고, 조회/삽입/수정/삭제 시의 장단점 정도를 훑어 보면서 플래시카드 어플리케이션에 적합한 패턴을 찾아보았습니다.
RDBMS에 트리 구조를 저장하기 위한 패턴
간단히 살펴본 결과 Parent-Child, Closure Table, Materialized Path, Nested Set 등이 있습니다.
Parent-Child
Parent-Child는 제가 ERD에 그린 것 처럼 자기 자신과 1:다 관계로 하여 부모(Parent) 식별자를 추가하는 패턴입니다.
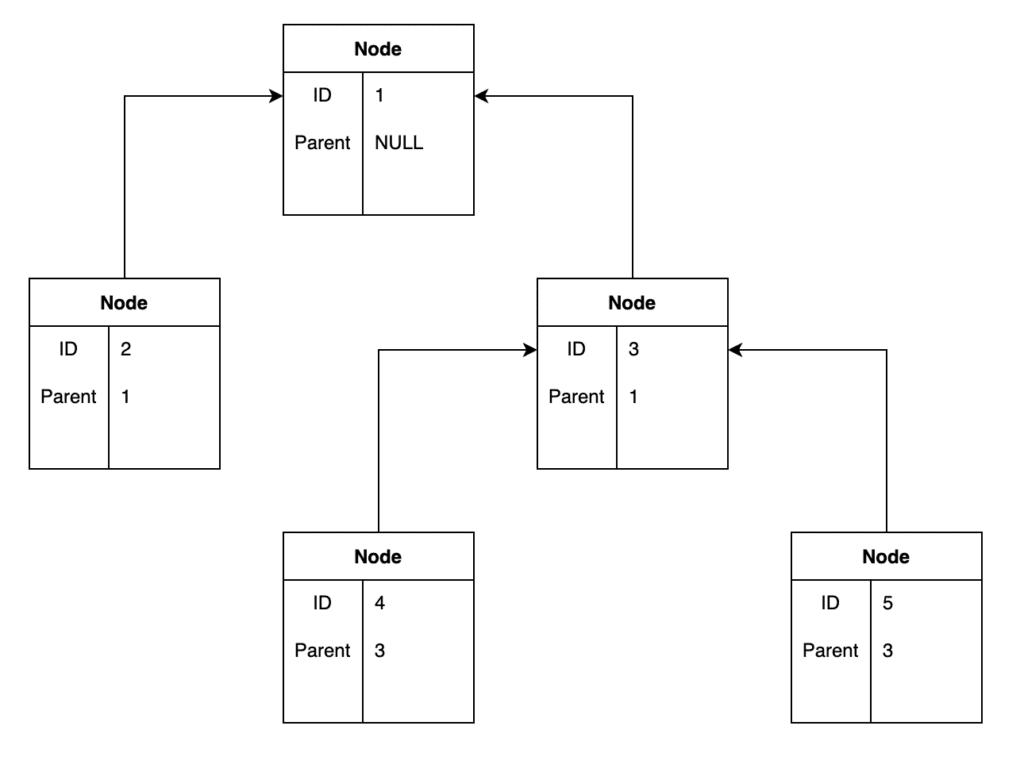 출처 : https://www.baeldung.com/cs/storing-tree-in-rdb
출처 : https://www.baeldung.com/cs/storing-tree-in-rdb
딱 봐도 새로운 개체를 추가하는 일이 굉장히 간단해 보입니다. 개체를 이동하는 일도 부모 식별자만 수정해주면 되니 굉장히 간단합니다.
하지만 부모를 삭제할 때는 하위 노드를 모두 찾아서 함께 삭제해 주어야하고, 전체를 조회하는 것도 깊이가 깊어지고 크기가 커지기 시작할 수록 많은 JOIN이 필요할 것으로 예상됩니다.
위 사진의 출처에서 조회 시에는 Recursive Common Table Expressions 을 추천합니다. MySQL은 8.0부터 지원(문서 링크)한다고 하며, sqlite 에서도 지원(문서 링크)합니다. 기본 구문 아는 수준인데 사용한다면 학습이 필요하겠습니다.
1
2
3
4
5
6
7
8
9
10
11
-- https://www.baeldung.com/cs/storing-tree-in-rdb
WITH RECURSIVE rectree AS (
SELECT *
FROM tree
WHERE node_id = 1
UNION ALL
SELECT t.*
FROM tree t
JOIN rectree
ON t.parent_id = rectree.node_id
) SELECT * FROM rectree;
Parent-Child 패턴 정리
- 장점: 삽입 / 이동(수정)
- 단점: 삭제 / 조회
본의 아니게 Parent-Child 패턴을 사용하면서, 다대다 관계로 만드는 것을 고려했던 것은 저도 모르게 조회 문제를 신경 썼기 때문이 아닐까 싶습니다.
플래시카드 어플리케이션은 메인 화면에서 모든 구조를 보여줘야하므로, 조회 작업이 가장 자주 일어나기 때문에 Parent-Child는 적합하지 않아 보입니다. 만약 사용하게 된다면 Recursive Common Table Expressions 를 활용해서 성능 문제 없이 조회를 할 수 있는지 확인해보는 것이 좋겠습니다.
Closure Table
Closure Table은 제가 다대다 관계로 모든 조상 정보와 모든 자식 정보를 저장한 후 조회 시에 사용하려고 했던 생각을 실제로 구현한 패턴입니다. 조금 아니다 싶었는데, 썩 괜찮은 방법이 많이 없나봅니다.

출처: https://www.baeldung.com/cs/storing-tree-in-rdb
자식이 없더라도 깊이가 깊으면 많은 row가 발생하는 등 조회할 때 빼고는 수정해야 할 row가 많아지므로, 조회가 많이 발생하는게 아닌 이상 사용하기 어려울 것 같습니다. 하지만 조회 성능이 중요한 경우 이어서 나올 패턴들을 고려하는게 적절하므로 굳이 사용할 이유는 없는 패턴으로 판단됩니다.
Closure Table 패턴 정리
- 장점: 조회
- 단점: 삽입 / 삭제 / 이동(수정)
Storing Paths 또는 Materialized Path
이 패턴은 개념적으로 어렵지 않으면서도, 사용법도 간편합니다.
1
2
3
4
5
6
7
8
9
id | ancestry | data
---+----------+----------
1 | NULL | root
2 | 1/ | Child 1
3 | 1/2/ | Child 1.1
4 | 1/2/ | Child 1.2
5 | 1/ | Child 2
6 | 1/5/ | Child 2.1
7 | 1/5/ | Child 2.2
위와 같은 테이블이 존재할 때, 아래와 같이 LIKE 절을 사용하여 자식들을 쉽게 조회할 수 있습니다.
1
SELECT * FROM nodes WHERE ancestry = '1/2' OR ancestry LIKE '1/2/%'
출처: https://makandracards.com/makandra/45275-storing-trees-in-databases
삽입 시에는 간단하게 하나의 row만 추가하면 됩니다. 자식이 없는 경우에는 삭제, 이동(수정) 시 해당 row만 영향을 받으므로 간단합니다.
자식이 있는 경우에는 삭제 또는 이동(수정) 시에 속해있는 자식들도 모두 수정을 해야하는 문제가 있습니다. 그래도 Closure Table 보다는 수정해야 할 row 수가 적어 부하가 적을 것으로 예상됩니다.
이러한 패턴의 대표적인 예로는 URL이 있으며, 대부분의 경우에 추천 할만 하지만, 참조 무결성 손실이 발생합니다.
Storing Paths 또는 Materialized Path 패턴 정리
- 장점: 조회 / 삽입 / (자식이
없는 경우) 삭제, 이동(수정) - 단점: (자식이
있는 경우) 삭제, 이동(수정) - 기타: 참조 무결성 손실
Nested Set
Storing Paths(또는 Materialized Path)가 LIKE 절에 문자열을 사용하여 조회 성능이 저하될 가능성이 있는 반면, Nested Set는 범위 질의를 통해 조회 성능을 향상시키지만 복잡하고, 조회 성능 말고는 장점이 없습니다.
아래의 예를 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
___________________________________________________________________
| Root |
| ____________________________ ____________________________ |
| | Child 1 | | Child 2 | |
| | __________ _________ | | __________ _________ | |
| | | C 1.1 | | C 1.2 | | | | C 2.1 | | C 2.2 | | |
1 2 3_________4 5________6 7 8 9_________10 11_______12 13 14
| |___________________________| |___________________________| |
|___________________________________________________________________|
id | parent_id | lft | rgt | data
---+-----------+-----+-----+----------
1 | 0 | 1 | 14 | root
2 | 1 | 2 | 7 | Child 1
3 | 2 | 3 | 4 | Child 1.1
4 | 2 | 5 | 6 | Child 1.2
5 | 1 | 8 | 13 | Child 2
6 | 5 | 9 | 10 | Child 2.1
7 | 5 | 11 | 12 | Child 2.2
Child 1의 자식들을 조회한다면, 아래와 같은 범위 질의를 사용할 수 있습니다.
1
SELECT * FROM nodes WHERE lft >= 2 AND rgt < 7 AND id != 2
출처: https://makandracards.com/makandra/45275-storing-trees-in-databases
갱신(삽입/수정/삭제)이 발생한다면 위의 경우 1~14 넘버링한 것도 변경해줘야 하는 귀찮은 일이 발생하겠네요. 갱신이 적게 발생하고, 조회 성능을 어떻게든 끌어올려야 하는 경우가 아닌 이상 쓸 이유가 없을 것 같아 보입니다.
MongoDB 문서(링크)에 있는 Nested Sets를 검색하다 보게 됐는데, 변경이 없는 static tree에 사용하기 최적이라고 언급하고 있습니다.
Nested Set 패턴 정리
- 장점: 조회
- 단점: 삽입 / 이동(수정) / 삭제
Outro
패턴을 보면서 느낀점은 계층 구조를 관계형 데이터베이스에 저장하기는 적합하지 않다는 것이었습니다. 물론 어플리케이션의 규모에 따라 달라지긴 하겠지만, 큰 규모를 고려한다면 다른 데이터베이스를 사용하는 것도 고려해야겠습니다.
직접 테스트해보지 않아서 정확하지는 않지만, 설명된 내용만으로 볼 때는 아래와 같이 정리할 수 있겠습니다.
- 조회 : Nested Set > Storing Paths(또는 Materialized Path) > Closure Table > Parent-Child
- 수정 : Parent-Child > Storing Paths(또는 Materialized Path) > Closure Table > Nested Set
- 삽입 : Parent-Child > Storing Paths(또는 Materialized Path) > Closure Table > Nested Set
- 삭제 : Parent-Child > Storing Paths(또는 Materialized Path) > Closure Table > Nested Set
일단 저는 배웠던 관계형 데이터베이스를 적용해보는 목적이 있고, 규모도 작은 것을 가정했기 때문에 Closure Table이나 Storing Paths(또는 Materialized Path)를 사용하여 설계를 계속 진행해야겠습니다.