데이터베이스 설계 연습1-4 물리 데이터 모델링
Intro
이전 글에서 논리 데이터 모델링을 수행한 결과는 아래와 같습니다.
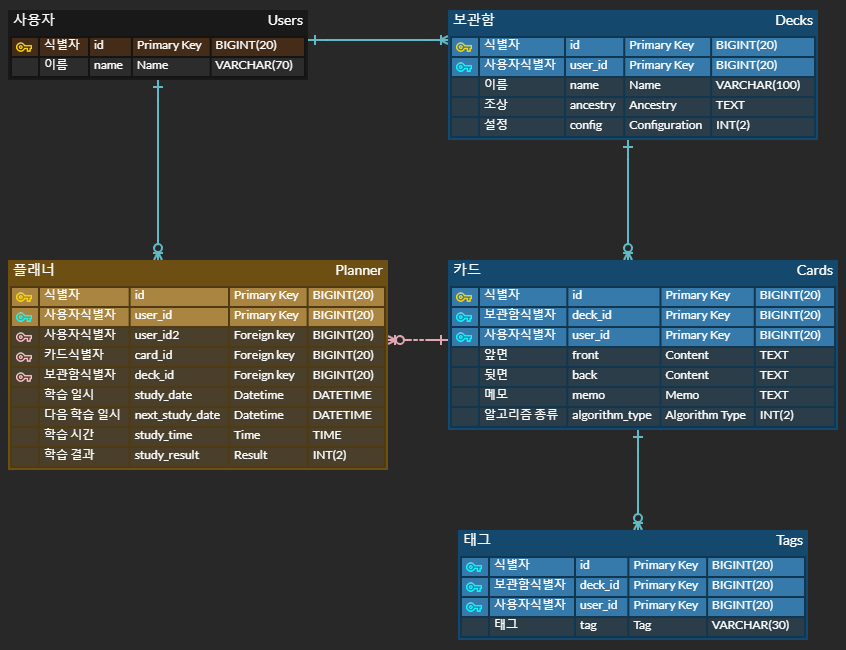
이를 바탕으로 먼저 이론적인 내용을 한번 훑어보고 물리 데이터 모델링을 진행하였습니다.
물리 데이터 모델링 이론 훑어보기
또 간단하게 DA 가이드의 물리 데이터 모델링 이해(링크)를 먼저 살펴봤습니다.
많은 사람들이 물리 데이터 모델링을 단순히 설계된 논리 데이터 모델의 개체 명칭이나 속성 명칭, 데이터 형태, 길이, 영역값등을 변환하는 것 정도로 생각하고 있다.
네 많은 사람들 중에 하나가 저 입니다.
그러나 물리적 데이터 모델링 단계는 논리 데이터 모델에서 도출된 내용 변환을 포함하여 데이터의 저장공간, 데이터의 분산, 데이터 저장 방법 등을 함께 고려하는 단계이다. 또한, 이 과정에서 결정되는 많은 부분이 데이터베이스 운용 성능(Performance)으로 나타나므로 소홀히 다루면 안된다.
소홀히 하고 싶지 않은데… 물리 데이터 모델링 이해를 포함해서 물리 데이터 모델링 관련한 문서가 가장 많은 10개나 됩니다.
- 물리 데이터 모델링 이해(링크)
- 물리 요소 조사 및 분석(링크)
- 논리-물리 모델 변환(링크)
- 반정규화(링크)
- 물리 데이터 모델 품질 검토(링크)
- 저장 공간 설계(링크)
- 무결성 설계(링크)
- 인덱스 설계(링크)
- 분산 설계(링크)
- 보안 설계(링크)
오프라인 어플리케이션으로 분산 설계나 보안 설계(접근 통제)를 할 일은 없으니 이번에는 넘어가야겠습니다.
이전 글에서 VARCHAR 글자 수 정하다가 불편해서 그냥 TEXT 사용하면 안되나에 대한 의문을 가졌는데, 비슷한 내용이 논리-물리 모델 변환 문서에 나와 있습니다.
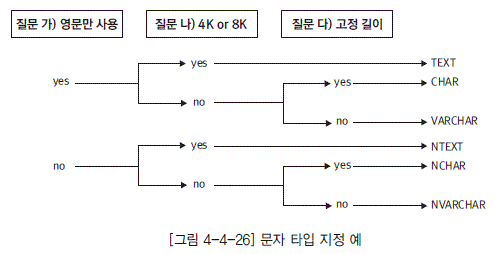
- 유니코드를 저장하는 데이터 타입에는 일반적으로 NCHAR, NVARCHAR등과 같이 앞에 N이 들어 가는 데이터 타입을 사용한다.
- 일반적인 문자들을 저장하는 데이터 타입은 4K 혹은 8K를 상한선으로 하고 있다. 물론 이 기준은 DBMS마다 조금씩 다르다.
그래도 그냥 TEXT 쓰면 안되나?에 대한 답은 안되기 때문에, 간단하게 chat GPT에 물어봤습니다.
모든 문자열을 TEXT로 저장하게 되면, 다음과 같은 문제가 발생할 수 있습니다.
- 성능 저하: 고정 길이나 최대 길이가 작은 문자열을 처리할 때, TEXT보다 CHAR나 VARCHAR가 처리 속도가 더 빠를 수 있습니다.
- 저장 공간 낭비: 길이가 일정한 데이터를 TEXT로 저장하면, 공간이 낭비될 수 있습니다. CHAR를 사용하면 공간 사용이 효율적일 수 있습니다.
- 유효성 검사: VARCHAR를 사용하면 최대 길이를 지정할 수 있어, 데이터의 유효성 검사를 간단하게 할 수 있습니다. TEXT는 길이 제한이 없기 때문에, 유효성 검사가 복잡해질 수 있습니다.
- 인덱싱 제약: 일부 데이터베이스 시스템에서는 TEXT 컬럼에 대한 인덱싱에 제약이 있을 수 있습니다. 이로 인해 쿼리 성능이 저하되거나, 인덱싱 자체가 불가능한 경우도 있습니다.
- 정렬 및 비교 연산: 문자열의 길이가 길어지면, 정렬이나 비교 연산의 성능이 저하될 수 있습니다. VARCHAR나 CHAR는 길이가 제한되어 있어, 이러한 연산에 대한 성능이 더 좋을 수 있습니다.
- 데이터 무결성: TEXT 타입은 길이 제한이 없기 때문에, 데이터 무결성을 유지하기 어려울 수 있습니다. 이로 인해 잘못된 데이터가 저장되거나, 예기치 않은 문제가 발생할 수 있습니다.
- 메모리 사용량 증가: 일부 데이터베이스 시스템에서는 TEXT 데이터를 처리하기 위해 더 많은 메모리를 사용할 수 있습니다. 이로 인해 전체적인 시스템 성능이 저하될 수 있습니다.
- 백업 및 복원 속도 저하: 대용량의 텍스트 데이터를 저장하게 되면, 데이터베이스의 백업 및 복원 속도가 저하될 수 있습니다. 이는 시스템 복구 시간을 늘리고, 데이터 손실 위험을 증가시킬 수 있습니다.
chat GPT라 일부 소설이 있을 수 있겠으나 어느정도 납득이 되는 부분이 있습니다.
이외의 많은 이론적인 내용들을 다 여기에 쓰기는 힘들 것 같습니다. 위 언급된 문서들을 참고하여 관리상 필요한 컬럼 추가, 무결성 설계, 인덱스 설계 등을 아래서 수행해보겠습니다.
관리상 필요한 컬럼 추가
많은 것을 추가하지는 않았고 카드 엔터티(Entity)에 2개의 컬럼을 추가하였습니다. 하나는 카드를 언제 생성했는지 알 수 있도록 생성일시 속성을 추가하였고, 다른 하나는 추후 다양한 학습 방식을 제공하기 위해 카드종류 속성을 추가하였습니다. 카드종류는 논리 데이터 모델링에서 식별되었어야 할 속성이 아니었나 생각됩니다.
DB 선택하기
오프라인 어플리케이션으로 MySQL을 사용할 필요는 없어서 SQLite(링크)를 생각했는데, 찾아보니 Java에는 굉장히 가벼운 H2(링크)가 존재해서 조금 고민이 됐습니다. 결국엔 SQLite를 사용하기로 결정했지만, 비교했던 부분들을 정리해 봤습니다.
자료형(Datatypes)
처음에 가장 당황했던 부분은 SQLite에 존재하는 자료형은 5개 밖에 없다는 것이었습니다. SQLite 에서는 자료형과 동의어로 Storage Class를 사용하는데, Storage Class 5가지는 아래와 같습니다.
- NULL. The value is a NULL value.
- INTEGER. The value is a signed integer, stored in 0, 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value.
- REAL. The value is a floating point value, stored as an 8-byte IEEE floating point number.
- TEXT. The value is a text string, stored using the database encoding (UTF-8, UTF-16BE or UTF-16LE).
- BLOB. The value is a blob of data, stored exactly as it was input.
BLOB(Binary Large OBject) : 보통 이미지, 오디오 등 크기가 큰 멀티미디어 객체 저장 시 사용. -Wikipedia(링크)
다른 자료형을 사용하면 아래와 같은 규칙을 갖고 자동으로 형변환이 되어 저장됩니다.
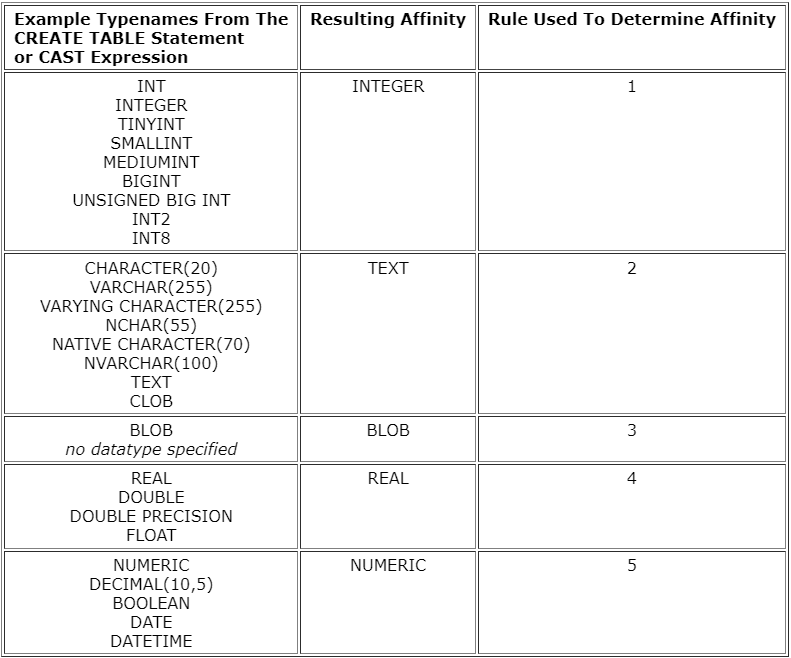
SQLite Datatype 문서(링크)
H2 의 경우 아래와 같이 다양한 자료형을 지원합니다.

H2 Datatype 문서(링크)
H2가 자료형을 다양하게 지원해서 좀 끌리기는 했지만, 이것 하나로 H2를 선택하기에는 그렇게 핵심적인 요소는 아니라 정보를 더 찾아봤습니다.
신뢰성(Reliability)
아직 비기능적 요소를 고려할 만큼의 지식은 없지만, reddit에 신뢰성에 대한 문제가 있을 수 있다는 글이 있어 H2의 FAQ 문서(링크)를 확인하였습니다. Is it reliable? 섹션에 있는 내용 중에 아래와 같은 내용이 있었습니다.
In addition to that, running out of memory should be avoided. In older versions, OutOfMemory errors while using the database could corrupt a databases.
이전 버전에 대한 문제라지만 찝찝함을 지울 수 없습니다. 시간들여 작성한 카드와 학습 기록이 손실되면 사용자 입장에서 너무 힘 빠지는 일이라, 이미 Anki를 사용하면서 몇년 동안 문제없이 SQLite인줄도 모르고 사용한 입장에서 SQLite에 마음이 기웁니다.
최종 선택은 SQLite
위에 작성했던 것 말고도 SQLite 에 대한 글 들을 더 찾아봤었습니다. 기억나는 걸로는 SQLite는 외래키(Foreign Key)를 설정 못한다는 블로그 글이 있어서 당황해서 찾아보니 2009년 부터 지원(SQLite 외래키 문서)하고 있었습니다. 몇 년 안된 글이었는데도 잘못된 정보를 제공하고 있으니, 저도 글을 좀 막쓰고 있어서 누구한테 피해주지 않을까 걱정됩니다. 조심해야겠습니다.
결국 신뢰성에서 SQLite의 손을 들어줄 수 밖에 없었고, 모바일 개발 시에도 SQLite 가 주로 사용(Android, iOS 기본 포함 / Android는 SQLite를 위한 라이브러리 제공)되는 것으로 판단 되어 추후에 모바일용 어플리케이션 만드는 것도 고려해서 SQLite로 최종 확정하였습니다.
SQL 작성 - 무결성 설계
바로 SQLite 용 테이블 생성 SQL을 작성하면서 무결성 설계한 내용을 적용하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
--사용자 테이블 생성
CREATE TABLE "Users" (
"id" INTEGER NOT NULL,
"name" TEXT NOT NULL,
PRIMARY KEY("id")
);
--보관함 테이블 생성
CREATE TABLE "Decks" (
"id" INTEGER NOT NULL,
"user_id" INTEGER NOT NULL,
"name" TEXT NOT NULL UNIQUE,
"ancestry" TEXT DEFAULT '1::',
"config" INTEGER DEFAULT 1,
FOREIGN KEY("user_id") REFERENCES "Users"("id") ON DELETE CASCADE,
PRIMARY KEY("id","user_id")
);
--카드 테이블 생성
CREATE TABLE "Cards" (
"id" INTEGER NOT NULL,
"deck_id" INTEGER NOT NULL,
"user_id" INTEGER NOT NULL,
"front" TEXT NOT NULL,
"back" TEXT,
"memo" TEXT,
"algorithm_type"INTEGER DEFAULT 1,
"create_date" TEXT DEFAULT 'datetime(''now'')',
"card_type" INTEGER NOT NULL,
PRIMARY KEY("id","deck_id","user_id"),
FOREIGN KEY("deck_id") REFERENCES "Decks"("id") ON DELETE CASCADE,
FOREIGN KEY("user_id") REFERENCES "Decks"("user_id") ON DELETE CASCADE
);
--태그 테이블 생성
CREATE TABLE "Tags" (
"id" INTEGER NOT NULL,
"deck_id" INTEGER NOT NULL,
"user_id" INTEGER NOT NULL,
"tag" TEXT NOT NULL,
PRIMARY KEY("id","deck_id","user_id"),
FOREIGN KEY("deck_id") REFERENCES "Cards"("deck_id") ON DELETE CASCADE,
FOREIGN KEY("user_id") REFERENCES "Cards"("user_id") ON DELETE CASCADE
);
--플래너 테이블 생성
CREATE TABLE "Planner" (
"id" INTEGER NOT NULL,
"user_id" INTEGER NOT NULL,
"card_id" INTEGER NOT NULL,
"deck_id" INTEGER NOT NULL,
"study_date" TEXT DEFAULT 'datetime(''now'')',
"next_study_date" TEXT NOT NULL,
"study_time" TEXT NOT NULL,
"study_result" INTEGER NOT NULL,
FOREIGN KEY("card_id") REFERENCES "Cards"("id") ON DELETE CASCADE,
FOREIGN KEY("user_id") REFERENCES "Users"("id") ON DELETE CASCADE,
FOREIGN KEY("deck_id") REFERENCES "Cards"("deck_id") ON UPDATE CASCADE,
PRIMARY KEY("id","user_id")
);
DB Browser for SQLite(링크)를 이용하니 ERD를 보면서 쉽게 SQL을 만들 수 있었습니다.
혼란스러웠던 점
플래너 테이블 생성하는 SQL을 작성할 때는 머리로 생각하고 있는 요구사항이 애매해서 조금 혼란스러웠던게 몇 가지 있었습니다.
- 학습 기록을 공부할 당시에 카드를 포함하던 보관함을 기준으로 학습 기록을 남길 것인가
- 카드가 삭제되면 해당 카드의 모든 학습 기록을 삭제할 것인가
첫 번째 문제는 카드가 다른 보관함으로 이동된다면 애초에 잘못된 위치에 있던 것이므로 카드를 따라 수정되는 것이 맞다고 생각했습니다. 그래서 Cards 테이블에서 보관함 식별자(deck_id)가 수정되면 이를 따라서 UPDATE 되도록 했습니다.
두 번째 문제는 카드가 삭제됐는데 학습 기록이 남아있다면, 무엇을 공부했었는지도 모른채로 정보가 남아있는 것은 별 의미가 없다고 생각했습니다. 그래서 학습 기록 삭제를 원하지 않을 경우 카드가 학습 대상에 포함되지 않게 하는 기능을 추가하는 것으로 결정하였습니다. 추후에 누적 학습 시간은 카드와 상관 없이 의미가 있다고 생각될 경우 새로운 학습 기록이 생길 때마다 별도로 저장하는게 좋을 것 같습니다.
인덱스 설계
인덱스가 필요할 정도로 데이터가 많이 쌓이는 일은 없을 것으로 예상되기는 하지만, 최악의 경우를 생각해서 인덱스 설계를 해봐야겠습니다.
인덱스 설계 이론적인 내용 살펴보기
인덱스 설계의 이론적인 내용을 위에서 살펴보지 못해서 여기서 간단하게 보겠습니다.
인덱스는 특정 응용 프로그램을 위해서 생성되는 것이 아니다. 최소의 인덱스 구성으로 모든
접근 경로를 제공할 수 있어야 전략적인 인덱스 설계가 된다. 따라서 인덱스 선정은 테이블에 접근하는 모든 경로를 수집하고 수집된 결과를 분석하여 종합적인 판단에 의해서 결정되는 것이 바람직하다.
접근 경로가 뭘 의미하는지는 아래와 같이 나와있습니다. 자세한 내용은 링크에서 보실 수 있습니다.
접근 경로는 테이블에서 데이터를 검색하는 방법으로,테이블 스캔과인덱스 스캔등이 있다. 접근 경로를 수집한다는 의미는 SQL이 최적화되었을 때인덱스 스캔을 해야 하는 검색 조건들을 수집하는 것이므로 데이터베이스 설계 시 혹은 완성되지 않은 프로그램에서 사용될 모든 접근 경로를 예측 하기는 불가능하다. 따라서 프로그램 설계서, 화면 설계 자료, 프로그램 처리 조건 등을 고려하여 예상되는 접근 경로를 수집하여야 한다. 수집은테이블 단위로 진행하고, 다음과 같은 점을 고려하여 접근 유형을 목록화한다.
- 반복 수행되는 접근 경로
- 분포도가 양호한 칼럼
- 조회 조건에 사용되는 칼럼
- 자주 결합되어 사용되는 칼럼
- 데이터 정렬 순서와 그룹핑 칼럼
- 일련번호를 부여한 칼럼
- 통계 자료 추출 조건
- 조회 조건이나 조인 조건 연산자
기본키/외래키 컬럼에 인덱스 생성
기본키와 외래키 컬럼을 통해 JOIN이 자주 발생하므로, 먼저 기본키와 외래키에 인덱스를 아래와 같이 설정하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
--사용자 테이블 기본키 인덱스 생성
CREATE INDEX "idx_user_pk" ON "Users" (
"id" DESC
);
--보관함 테이블 기본키/외래키 인덱스 생성
CREATE INDEX "idx_decks_pk" ON "Decks" (
"id" DESC,
"user_id" DESC
);
--카드 테이블 기본키/외래키 인덱스 생성
CREATE INDEX "idx_cards_pk_fk" ON "Cards" (
"id" DESC,
"deck_id" DESC,
"user_id" DESC
);
--태그 테이블 기본키/외래키 인덱스 생성
CREATE INDEX "idx_tags_pk_fk" ON "Tags" (
"id" DESC,
"deck_id" DESC,
"user_id" DESC
);
--플래너 테이블 기본키/외래키 인덱스 생성
CREATE INDEX "idx_planner_pk_fk" ON "Planner" (
"id" DESC,
"user_id" DESC
);
CREATE INDEX "idx_planner_fk" ON "Planner" (
"card_id" DESC,
"deck_id" DESC
);
조회 조건에 사용되는 컬럼에 인덱스 생성
조회 조건에 사용되는 컬럼이 꽤나 많은데 다 추가하는게 맞는건가 고민이 됩니다. 일단은 이론대로 따라가 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
--보관함 테이블의 조상 컬럼
CREATE INDEX "idx_decks_ancestry" ON "Decks" (
"ancestry" DESC
);
--카드 테이블의 학습 내용관련 컬럼
CREATE INDEX "idx_cards_for_search" ON "Cards" (
"front" DESC,
"back" DESC,
"memo" DESC
);
--태그 테이블의 태그 컬럼
CREATE INDEX "idx_tags_tag" ON "Tags" (
"tag" DESC
);
--플래너 테이블의 다음 학습 일정 컬럼
CREATE INDEX "idx_planner_next_study_date" ON "Planner" (
"next_study_date" DESC
);
단순히 인덱스만 추가한다고 빨라지는 것은 아니라고 이론적으로 많이 배웠는데 너무 마구잡이로 추가하는 느낌이라 썩 내키지가 않는 기분입니다. 특히나 TEXT 속성이라 더욱 그렇습니다.
SQLite Query Optimizer Overview(링크) 문서를 보면, WHERE 절에서 LIKE 를 사용할 보관함 테이블의 ancestry 컬럼과 = 연산자를 사용할 태그 테이블의 tag 컬럼, 플래너 테이블의 next_study_date 컬럼은 그래도 인덱스를 사용하기는 할 것으로 판단됩니다. 그런데 카드테이블에 있는 front, back, memo 컬럼은 문장이 될 수도 있기 때문에 인덱스가 효용이 있을지 의문입니다. 어렴풋이 Full Table Search extension을 들은적이 있는데 확인해 봐야겠습니다.
인덱스는 언제든지 삭제할 수 있으니, 이후에 성능 측정하는 방법도 공부해서 비교해보는게 좋겠습니다.
Outro
물리 데이터 모델링이 오래 걸리기는 했지만 생각보다는 그래도 빠르게 끝을 냈습니다. DB 선택하는 과정에서 많은 부분을 고려하지 않았고, 이론적인 내용들도 많은 부분 생략했기 때문이라 생각됩니다.
다음에는 프론트엔드랑 백엔드도 배우고 하면서 규모도 커지면 더 많은 부분을 고려할 수 밖에 없을테니 그때 다시 해봐야겠습니다. 아래 내용처럼 블록 사이즈를 고려한 테이블 설계도 해보고 싶은데, 아직 어떻게 시작해야할지 조차 감이 안잡힙니다.
칼럼 데이터 길이 합이 1 블록(Block) 사이즈보다 큰 경우 수직 분할을 고려한다. 1 블록 사이즈보 다 크면 체인이 발생하여 속도 저하 현상을 유발한다.
일단은 다음을 기약하고, 이제는 데이터베이스 연동하고 구현을 시작해봐야겠습니다.