프로그래머스 Lv. 1 실패율
Intro
오늘은 프로그래머스 Lv. 1 문제인 실패율을 풀어봤습니다. 2019 KAKAO BLIND RECRUITMENT 문제라 그런지 다른 Lv. 1에 연습문제에 비해서는 조금은 더 난이도가 있는 느낌입니다.
절대적으로는 쉬운문제라 카카오의 공식적인 문제 해설(링크)은 몇 줄 안됩니다.
문제
문제를 간단히 설명 드리면, N 개의 스테이지가 있는 게임에서 여러 사용자가 도달한 스테이지 정보가 있을 때 각 스테이지 실패율을 기준으로 스테이지 번호를 내림차순으로 정렬하는 문제입니다. 실패율이 같을 때는 스테이지 숫자를 기준으로 오름차순이 되어야 합니다.
1
2
실패율 = 스테이지에 도달했으나 아직 클리어하지 못한 플레이어의 수 / 스테이지에 도달한 플레이어 수
* 스테이지에 도달한 플레이어수가 0인 경우 실패율은 0
추가적인 제한사항 및 설명은 링크 참조
해결 전략
어제 다짐했던대로 아이디어가 떠오르는대로 먼저 빠르게 구현해봤습니다.
아래 주어진 테스트 케이스를 볼 때, 각 스테이지 번호로 순회하면서 스테이지 번호와 stages 배열의 값이 같은 것의 갯수를 더하면 스테이지에 도달했으나 아직 클리어하지 못한 플레이어 수, 즉, 실패율의 분자가 되고, stages 배열의 값이 스테이지 번호 이상인 것의 갯수를 더하면 스테이지에 도달한 플레이어 수, 즉, 실패율의 분모가 되는 것을 쉽게 파악할 수 있습니다.
| N | stages | result |
|---|---|---|
| 5 | [2, 1, 2, 6, 2, 4, 3, 3] | [3,4,2,1,5] |
| 4 | [4,4,4,4,4] | [4,1,2,3] |
그래서 스테이지 번호 마다 stages 배열을 순회하면서 각 스테이지 실패율을 구하여 저장한 후에 실패율 별로 스테이지 번호를 정렬해서 출력하는 것을 해결 전략으로 세웠습니다.
구현
먼저 각 스테이지별 실패율을 계산하는 코드를 구현한 결과를 가장 단순하게 구현하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int[] answer = new int[N];
// 스테이지별 실패율 계산하기
double[] failRate = new double[N];
for (int i = 1; i <= N; ++i) {
int challenger = 0; // 스테이지 도전 인원
int failure = 0; // 스테이지 실패 인원
for (int j = 0; j < stages.length; ++j) {
// 스테이지 도전 인원(분모) 카운트
if (stages[j] >= i) ++challenger;
// 스테이지 실패 인원(분자) 카운트
if (stages[j] == i) ++failure;
}
// 스테이지별 실패율 계산
if (challenger != 0) failRate[i-1] = (double) failure / challenger;
}
다음은 스테이지를 실패율 기준 내림차순 정렬한 위치를 계산하는 것을 구현한 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
// 실패율 내림차순 순위 계산
int[] rankDesc = new int[N]; // 스테이지의 정렬 순위 저장
for (int i = 0; i < N; ++i) {
for (int j = i + 1; j < N; ++j) {
// 앞의 실패율이 작을 경우 내림차순이므로 앞 스테이지를 뒷 순위로 이동
if (Double.compare(failRate[i], failRate[j]) == -1) ++rankDesc[i];
// 앞뒤의 실패율이 동일하거나 뒤의 실패율이 작을 경우
// 뒷 스테이지를 뒷 순위로 이동
else ++rankDesc[j];
}
// 앞에서 구한 순위를 인덱스로 하여 스테이지 번호 저장
answer[rankDesc[i]] = i + 1;
}
조금 더 개선해보기
스테이지별 실패율 계산 개선하기 1
먼저 스테이지별 실패율 계산하는 것을 개선해 봤습니다.
stages 배열은 순서 정보가 없으므로 먼저 정렬합니다. 그리고 필요한 만큼만 stages 배열을 순회하기 위해 각 스테이지 번호마다 stages 배열에서 어디까지 이동했는지 저장합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Arrays.sort(stages);
// 스테이지별 실패율 계산하기
int tracker = 0; // 순회 인덱스 추적용 변수
for (int i = 1; i <= N; ++i) {
int challenger = 0; // 스테이지 도전 인원
int failure = 0; // 스테이지 실패 인원
// 앞서 stages가 정렬되었으므로,
// stages 배열의 특정 위치의 요소 포함, 오른쪽의 모든 요소의 개수는 스테이지 도전 인원이 된다.
if (tracker < stages.length && stages[tracker] == i) challenger = stages.length - tracker;
// tracker가 인덱스를 벗어나면, 나머지 스테이지는 도전자가 없는 것이므로 for문 종료
else if (tracker >= stages.length) break;
// 스테이지 실패 인원 확인
while (tracker < stages.length && stages[tracker] == i) {
++failure;
++tracker;
}
// 스테이지별 실패율 계산
if (challenger != 0) failRate[i-1] = (double) failure / challenger;
}
stages 배열의 길이를 M이라고 할 경우, (순위 계산 제외) 기존 코드의 시간 복잡도는 O(NM)이었고, 개선한 코드는 Arrays.sort()가 O(NlogN) 이므로 O(NlogN + N + M)이 되었습니다.
실제 속도가 세자리 수까지 나오던게 두자리 수까지 줄었습니다.
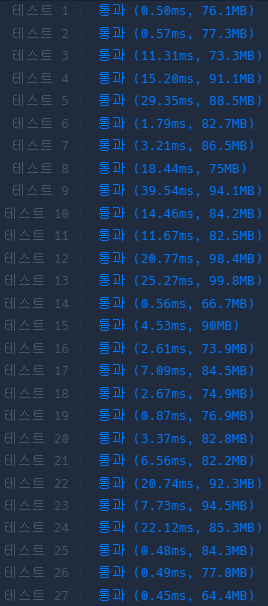
스테이지별 실패율 계산 개선하기 2
다른 방법을 찾다가 또 시간이 너무 흘러서 chatGPT에 물어봤습니다. challenger와 failure 배열을 별도로 만드는 것을 추천하는데, 또 틀린 코드를 제시해 줬습니다. 그래서 앞의 조금 개선한 코드에서 stages 배열 정렬 후 challenger를 계산했던 아이디어와 합쳐서 수정해봤습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Arrays.sort(stages);
int challengers[] = new int[N];
int failures[] = new int[N];
// 스테이지 도전 실패 인원 계산
for (int stage : stages) {
if (stage <= N) ++failures[stage-1];
}
// 스테이지별 실패율 계산하기
// 스테이지 도전 인원 계산을 위한 스테이지별 누적 실패 인원
int cumulativeFailures = 0;
for (int i = 0; i < N; ++i) {
challengers[i] = stages.length - cumulativeFailures;
cumulativeFailures += failures[i];
// 스테이지별 실패율 계산
if (challengers[i] != 0) failRate[i] = (double) failures[i] / challengers[i];
}
하지만 시간복잡도는 O(NlogN + N + M)으로 차이가 없습니다.
공간 복잡도는 기존의 answer 배열이 있던 O(N)에서 O(N+N+N) = O(3N) 이지만, 상수항 무시하므로 O(N)으로 동일합니다.
테스트 결과도 큰 차이가 없습니다. 가독성이 좀 좋아졌다는 것에 만족해야겠습니다.
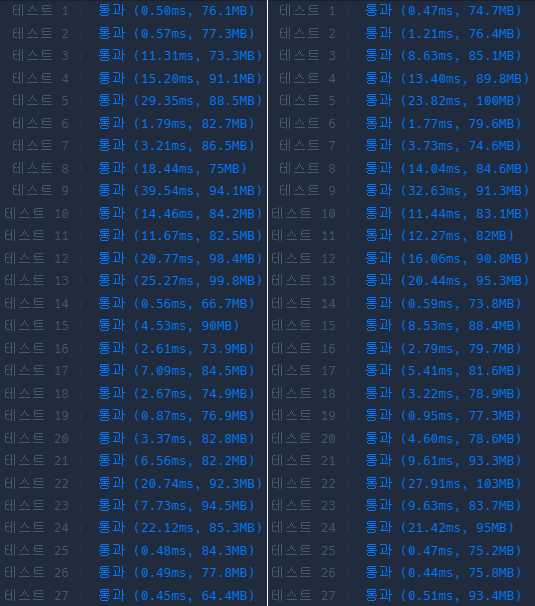
실패율 내림차순 순위 계산 개선하기
처음에는 동일한 실패율에 대해 TreeMap에서 어떻게 처리해야할지 아이디어가 안떠올라서 순위 저장하는 배열을 별도로 만들어 저장을 했었습니다. 그래서 또 chatGPT에게 여기서 TreeMap을 어떻게 활용하면 좋을지 물어봤습니다.
그랬더니 TreeMap value의 type으로 ArrayList를 추천합니다. 아… 어려운 것도 아닌데 저는 왜 이런생각을 못하는 건지 자책을 하게 됩니다.
많은 부분을 수정해서 전체 코드를 아래와 같이 작성하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
import java.util.*;
class Solution {
public int[] solution(int N, int[] stages) {
Arrays.sort(stages);
int challengers[] = new int[N];
int failures[] = new int[N];
// 스테이지 도전 실패 인원 계산
for (int stage : stages) {
if (stage <= N) ++failures[stage-1];
}
// 스테이지별 실패율 계산하기
Map<Double, List<Integer>> failRateMap = new TreeMap<>(Collections.reverseOrder());
// 스테이지 도전 인원 계산을 위한 스테이지별 누적 실패 인원
int cumulativeFailures = 0;
for (int i = 0; i < N; ++i) {
challengers[i] = stages.length - cumulativeFailures;
cumulativeFailures += failures[i];
// 스테이지별 실패율 계산
double failRate = 0;
if (challengers[i] != 0) failRate = (double) failures[i] / challengers[i];
// 실패율 내림차순 순위 정렬해서 저장
if (failRateMap.containsKey(failRate)) {
failRateMap.get(failRate).add(i + 1);
} else {
List<Integer> stageList = new ArrayList<>();
stageList.add(i + 1);
failRateMap.put(failRate, stageList);
}
}
// 정답 배열 생성
int[] answer = new int[N];
int index = 0;
for (List<Integer> stageList : failRateMap.values()) {
for (int stage : stageList) {
answer[index] = stage;
++index;
}
}
return answer;
}
}
기존에는 실패율 배열(failRate[])에 저장하는 코드의 시간복잡도가 O(1)이었지만, Red-Black Tree를 사용하는 TreeMap으로 인해, 탐색 시 O(logN), 삽입 시 O(logN)이므로 O(logN)으로 증가했습니다. 정답 배열 생성 시에는 기존 O(N^2) 에서 O(N)으로 개선되었습니다.
공간 복잡도 변화는 없습니다.
하지만 실제로는 성능이 외려 전체적으로 떨어진 것으로 보입니다. 변경된 부분만 보자면 O(N^2) 에서 O(logN + N)이 됐지만, 더 안좋아 졌습니다.
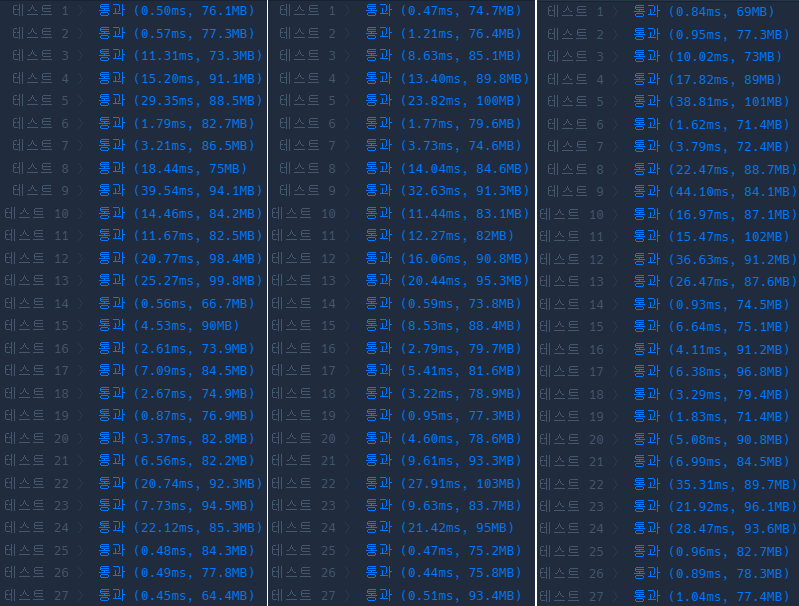
흠… 아무래도 제가 고려하지 못한 부분이 있는 것 같지만 현재는 보이지 않습니다.
Outro
이번에 처음부터 생각했던 자료구조인 TreeMap 을 사용해보겠다고 고집부리지 않고, 생각나는 단순한 아이디어를 빠르게 확인해봐서 마음 편하게 개선을 시도해볼 수 있었습니다.
이번 문제를 풀면서 배운걸 정리해보면,
- 알고리즘 문제는 최대한 단순하게 풀어보는 것이 좋다.
- 이론과 실제는 다르다.
코드 개선하는데 재밌어서 시간 가는 줄 모르고 하다가 너무 많은 시간을 쓴 것 같습니다. 한동안은 Lv. 1 수준 문제는 양으로 승부하고, Lv. 2 부터는 다시 한 문제씩 공들여 풀어봐야겠습니다.